ICLR2025
Mitigating Spurious Correlations in Zero-Shot Multimodal Models
在论文中,作者通过调整图像嵌入(image embeddings)的方向,来缓解 VLM(Vision-Language Models)中的伪相关(spurious correlations)。核心思想是通过一个“平移操作”来调整图像嵌入,使其减少对伪特征的依赖,进而提高模型在“零样本”(zero-shot)分类任务中的鲁棒性。以下是具体的公式推导过程:
群体鲁棒性
论文首先介绍了群体鲁棒性的概念,这意味着在面对特定的“伪特征”时,模型需要在多个群体中保持良好的预测性能。伪特征是那些与目标标签无关,但在训练数据中与标签相关的特征。文中提到,提升群体鲁棒性的目标是最大化每个群体的准确性。
公式 4:群体准确性,表示了群体准确性的目标函数:
其中是来自群体, (y是目标标签,a是伪特征)的图像嵌入,是一个线性分类器的权重,表示群体的准确性。
论文中的Lemma 1 给出了群体准确性的数学推导公式,依赖于图像嵌入的均值和协方差矩阵。这一定义帮助我们理解如何通过改变图像嵌入的分布来提高群体的准确性。
伪关联特征向量
论文的创新点之一是提出了一种“平移”操作,它将图像嵌入从伪特征的方向上调整,使模型减少对伪特征的依赖:
其中是伪特征方向的平移向量。论文进一步推导了平移向量的最优方向,公式(7)给出了最优平移向量的计算方法:
其中P是一个矩阵,它定义了平移的方向。根据推导,最优的平移向量实际上是伪特征的负方向,即图像嵌入在伪特征的方向上的投影的负方向。为了获得伪特征方向,有效地结合文本和图像嵌入至关重要。作者首先定义了伪相关向量(Spurious Feature Vector),使用伪文本嵌入来引导图像嵌入走向最佳状态
其中是文本编码器,是描述伪特征的文本提示,例如 “a photo with a water background”(含水背景的图片)。
由于模型在训练过程中可能错误地依赖于某些伪特征a(例如背景颜色、光照条件等),我们可以将图像嵌入分解为: 论文中通过对原版提示修改为得到伪提示
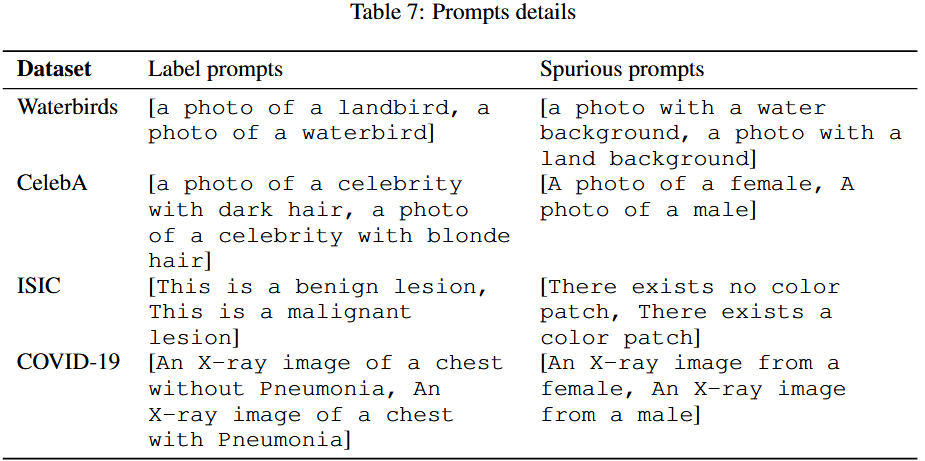
TIE*
TIE 和 TIE* 方法 TIE 的主要思想是通过引导图像嵌入沿着伪特征的负方向平移,从而减小伪特征对分类的影响。在没有标签的情况下,TIE* 采用一种“伪标签”的方式,通过零样本推断伪特征来进行图像嵌入的平移操作(Translation Operation):
而在没有伪标签的情况下,TIE* TIE* 采用图像嵌入和伪特征文本描述之间的相似度来推断伪特征标签。以下公式进行伪标签推断(公式 9):

首先,我们利用 spurious prompts 来计算 spurious vectors。然后,我们使用 CLIP 模型来推断每个样品的虚假标签。随后,我们根据伪关联标签的方向变换图像嵌入。最后,我们使用这些平移后的 embedding 来执行 zero-shot 分类任务
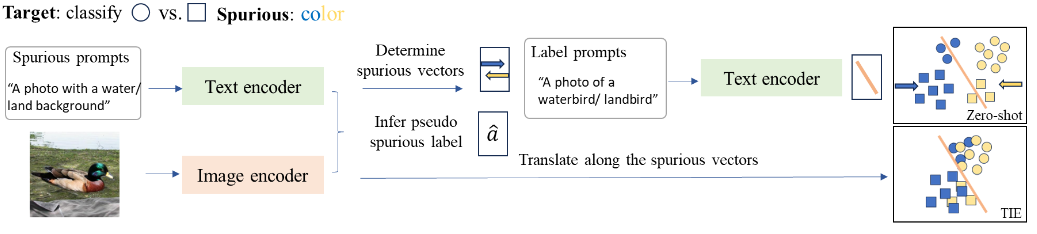
实验
比较了 TIE 与其他现有方法(如 ROBOSHOT、Orth-Cali 等)在下面数据集上的表现
- Waterbirds (Koh et al., 2021; Sagawa et al., 2019),
- CelebA (Liu et al., 2015),
- ISIC (Codella et al., 2019),
- COVID-19 (Cohen et al., 2020),
- FMOW (Christie et al., 2018).
通过计算Worst-Group Accuracy(最差群体准确率,简称 WG),Accuracy Gap(准确率差距,简称 Gap)是指平均准确率(Average Accuracy)与最差群体准确率之间的差距。证明了 TIE 在减少伪特征影响方面的有效性。通过上述公式推导,作者展示了如何在没有训练的情况下,通过平移图像嵌入来消除伪特征的影响,从而提高零样本分类任务中的群体鲁棒性。
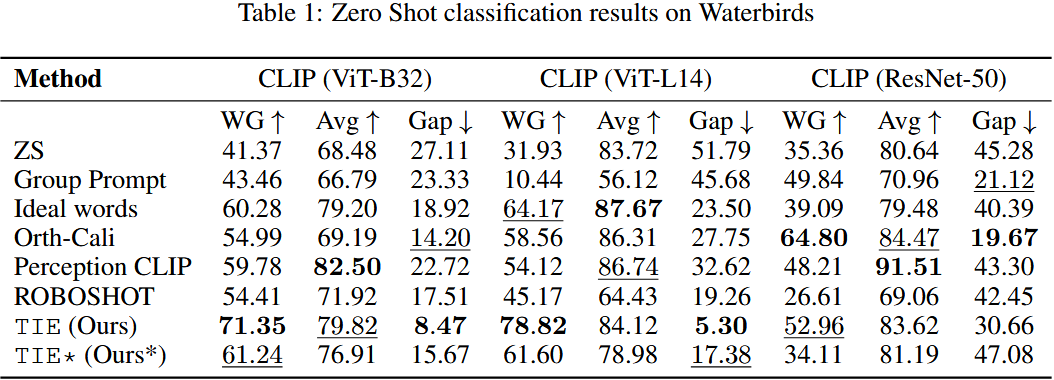
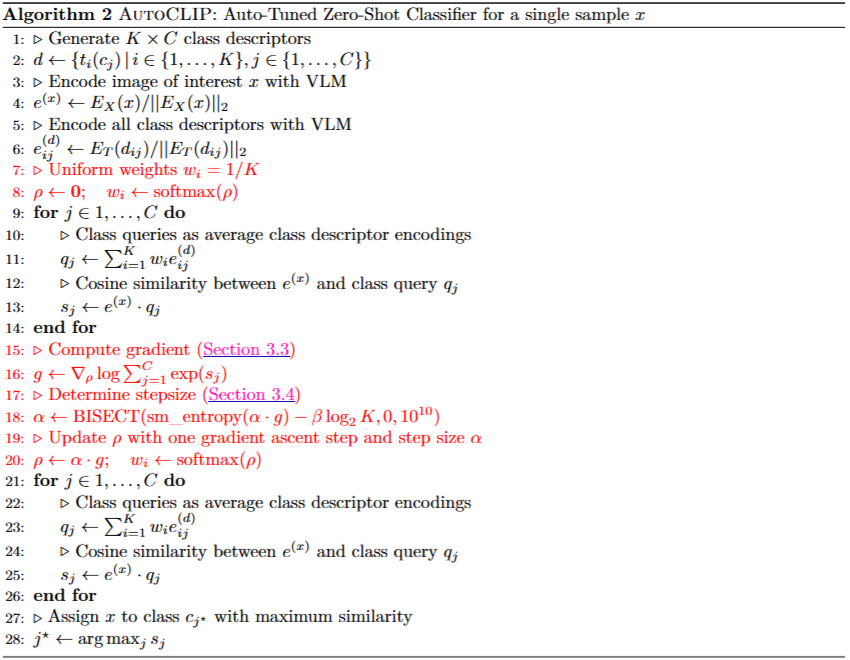
AutoCLIP: Auto-tuning Zero-Shot Classifiers for Vision-Language Models
AutoCLIP的算法过程旨在通过动态调整每个提示模板的权重,优化zero-shot分类器的性能。与传统方法不同,AutoCLIP根据每张图像与不同提示模板之间的相似度,在推理阶段对这些模板进行自适应加权,无需训练从而提高图像分类的准确性。
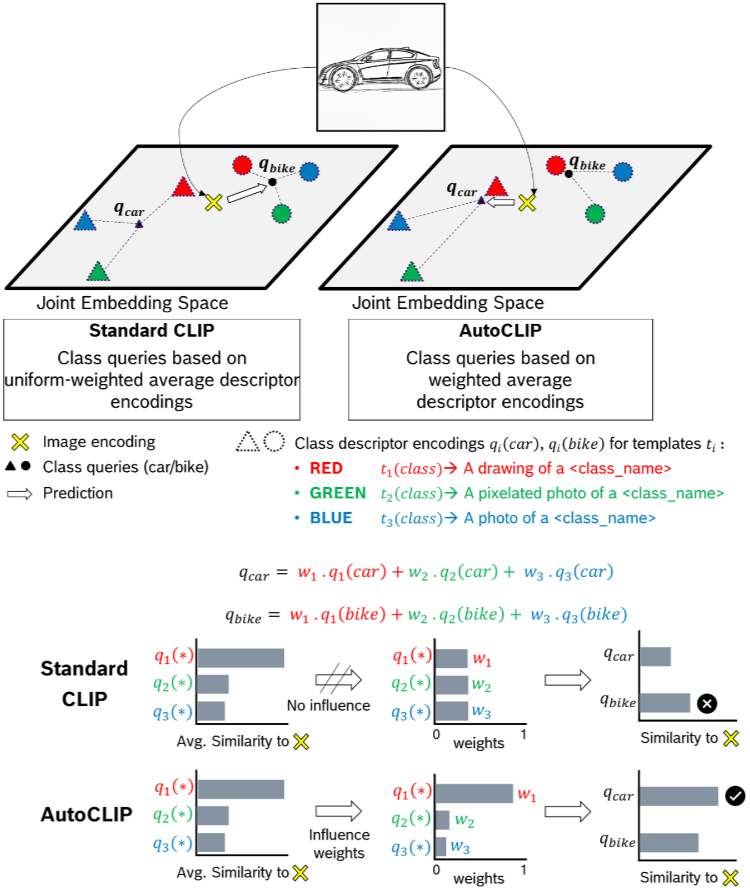
在AutoCLIP之前,标准的zero-shot分类方法大致如下,这种方法的问题在于,所有模板的权重相同,而实际上某些模板可能比其他模板更能描述当前图像。因此,AutoCLIP的创新在于为每个图像自适应调整这些模板的权重:

下面是AutoCLIP的主要流程:
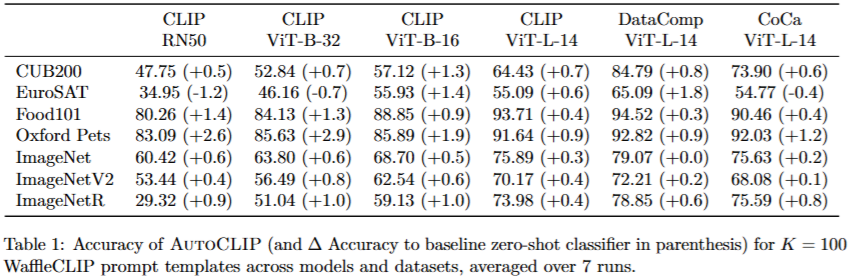
AutoCLIP在多种数据集和VLM上均能够提高zero-shot分类器的准确性,且其计算开销相对较小。
ZeroDiff: Solidified Visual-semantic Correlation in Zero-Shot Learning
CLIPure: Purification in Latent Space via CLIP for Adversarially Robust Zero-Shot Classification
用扩散模型消除扰动提高CLIP的鲁棒性的方法
A Simple Framework for Open-Vocabulary Zero-Shot Segmentation

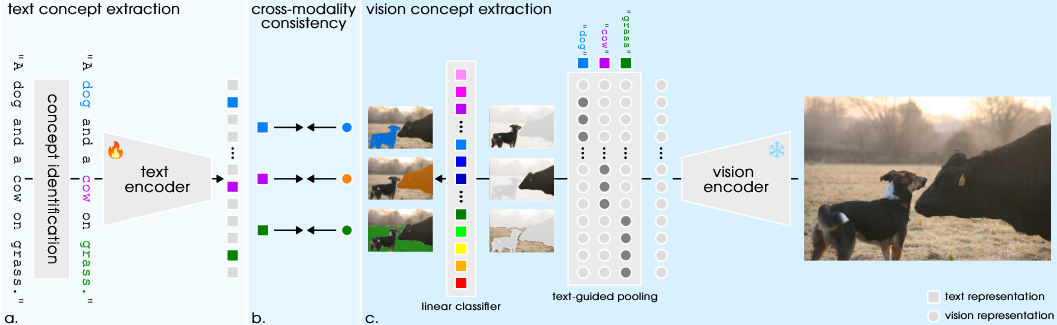
文本概念识别(Textual Concept Identification)
通过对词汇进行词性标注(POS tagging),我们可以识别出名词短语(noun phrases,NP)我们对名词短语进行细化处理,只保留名词及其第一个复合词(如 "dog" 或 "dog bed")识别的文本概念通过对其在文本密集表征(即一段prompt中所有的token表示)中的索引进行平均得到其全局表示:
线性映射到图像空间
视觉概念识别(Visual Concept Identification)
通过将图像嵌入到视觉编码器 中,我们得到图像的稠密视觉表示 然后,我们将从文本中获得的概念映射到视觉空间,计算每个patch的视觉表示与全局文本概念的相似度,得到每个局部视觉表示的加权平均:
最终的全局视觉概念通过相似度加权求和得到:
跨模态一致性(Cross-modality Consistency)与损失函数
- 全局一致性(Global Consistency):计算图像和文本之间的全局相似度,确保图像的全局表示和文本的全局表示之间有高的一致性。学习目标是最大化图像和文本对之间的相似度,同时最小化不匹配对之间的相似度。损失函数为:
- 概念级一致性(Concept-level Consistency):
- 文本概念的表示:首先,文本编码器将文本描述(例如,“a dog on the grass”)转化为多个概念的嵌入(如“dog”和“grass”)。
- 图像块的视觉表示:图像通过视觉编码器(如ViT)处理后,图像被分割为多个较小的图像块(patches),每个块都有一个对应的视觉表示。
- 通过计算每个图像块的视觉表示和文本概念嵌入之间的相似度,SimZSS能够确定图像块属于哪个概念。 概念级一致性损失可以通过以下公式表示(是由视觉和文本概念之间的相似度计算得出的概率分布。):
最终,SimZSS的整体损失函数是全局一致性损失和概念级一致性损失的加权和:
训练
SimZSS只训练文本编码器,而视觉编码器保持冻结。通过跨模态一致性训练,SimZSS能够在没有训练标签的情况下,利用图像和文本的对齐进行零样本和开放词汇的分割任务。这一过程通过优化全局一致性和概念级一致性来保证图像和文本之间的高质量对齐,使得模型能够根据文本描述进行准确的图像分割。
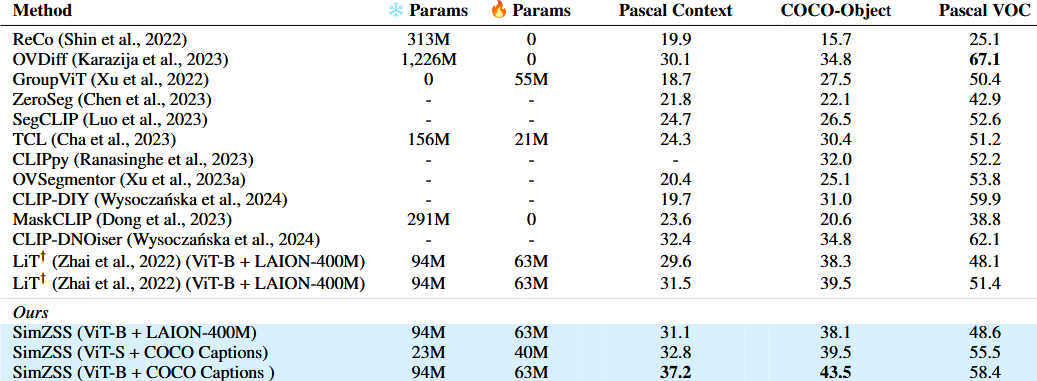
实验
论文做了Zero-shot foreground segmentation, Zero-shot segmentation, Zero-shot classification on ImageNet-1k三个实验
零样本分割
文本描述中的概念(如“dog”或“tree”)通过文本编码器提取出来,并映射到视觉空间。这些文本概念表示会与图像的视觉表示进行对比,计算文本概念和每个视觉块的相似度。
每个图像块通过计算相似度会被分配一个文本概念,表示这个图像块属于某个对象类别(例如,图像块可能包含“dog”或“tree”)。为了实现像素级别的分割,SimZSS执行以下步骤:
基于文本概念的查询:SimZSS首先通过文本概念与图像块进行匹配,确定每个图像块所属的类别。
上采样(Upsampling):SimZSS将图像块的表示映射回像素级别。在这个过程中,SimZSS会使用上采样技术,将每个图像块的分类结果推断到更高分辨率的图像中,最终生成像素级的分割掩码(segmentation mask)。
SimZSS通过加权相似度计算和像素级别的相似度来处理块内多类别的情况。每个像素的类别标签由多个可能的概念通过加权相似度得出,而不仅仅是图像块的单一标签。最终,这些标签通过上采样等技术传播到像素级别,实现细粒度的分割。
总结
作者在这样回复的审稿人 The statement outlines two necessary conditions for achieving zero-shot open-vocabulary segmentation without additional supervision:
- Grouping of local representations: For zero-shot segmentation to succeed, the local representations of similar objects must be clustered together in the embedding space. If this grouping does not occur, achieving good segmentation performance is impossible, regardless of the quality of the text encoder. This is because, during inference, the text encoder’s sole role is to generate the weights for the linear classifier.
- Alignment of text and vision modalities: The text encoder must be well-aligned with the vision modality. Without such alignment, the embeddings of a class's textual description will not closely correspond to the local representations of pixels or patches associated with that class. Consequently, the resulting linear classifier will lack discriminative power, leading to poor zero-shot segmentation performance. 简单理解:在零样本分割中,文本编码器的作用是生成每个类别的描述性的权重(或者称为线性分类器的“权重”)。这些权重会被用来与图像的局部表示进行比较,从而决定哪些图像区域属于某个类别。如果相似的物体或区域在嵌入空间中的表示分散得过于离散,那么即使文本编码器非常好,它也无法生成有效的匹配权重。最终,分类器的输出也不会准确,导致分割效果差。 同时文本和视觉模态的对齐是确保跨模态一致性的关键。如果文本和视觉表示不对齐,图像中描述物体的区域将与文本描述的类别不匹配。换句话说,文本中的“dog”描述和图像中的狗的局部表示如果没有良好的对齐,文本编码器生成的描述性嵌入就无法有效地与图像中的区域进行匹配。
SimZSS的跨模态一致性(Cross-modality Consistency)是该模型核心的关键之一,它通过有效地对齐视觉和文本信息来指导零样本和开放词汇的图像分割任务。跨模态一致性确保了文本描述中的概念能够正确地映射到图像中的视觉区域,从而实现高效的零样本分割