Awesome Open World Object Detection
本文主要基于这篇综述总结:
Li, Y., Wang, Y., Wang, W., Lin, D., Li, B., & Yap, K. H. (2024). Open World Object Detection: A Survey. IEEE Transactions on Circuits and Systems for Video Technology. https://doi.org/10.1109/TCSVT.2024.3480691
开放世界对象检测 (OWOD) 结合了对象检测、增量学习和开放集识别的功能。这三个研究领域成对组合成对,形成增量目标检测 (ILOD)、分布外检测 (OOD) 和开放世界识别 (OWR) 研究主题。
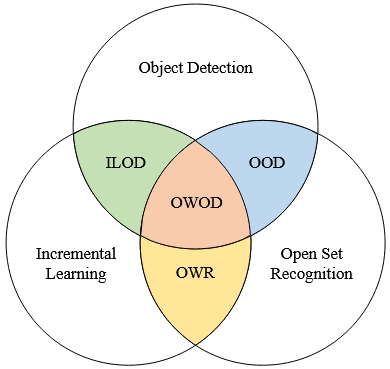
增量学习是一种机器学习方法,它允许对现有模型进行增量更新,而无需重新训练整个模型。在 OWOD 中,增量学习可以通过接收新数据或新任务来逐渐提高模型的性能,而不会对现有知识造成太大干扰。模型训练中存在一个常见缺陷,称为灾难性遗忘,其中机器学习模型(尤其是基于反向传播的深度学习方法)在新任务上训练时,通常会表现出与先前任务相比的显著性能下降。
灾难性遗忘的主要原因之一是传统模型假设数据分布是固定的或平稳的,并且训练样本是独立的且分布相同的。因此,模型可以重复看到所有任务的相同数据。但是,当数据成为连续数据流时,训练数据的分布是非平稳的。随着模型不断从这种非平稳数据分布中学习,新知识会干扰旧知识,导致模型性能迅速下降,甚至完全覆盖或忘记以前学习的知识。
将 OVOD 与开放世界对象检测 (OWOD) 进行比较, 这两个应用程序都扩展了对象检测系统的功能,使它们能够在更加动态和不可预测的环境中运行。但是,OVOD 主要使用开放词汇表,利用语言和视觉预训练来识别新对象。相比之下,OWOD 不仅检测已知和未知的物体,而且在不忘记以前学习过的类的情况下,将这些未知物体逐渐学习成新的已知类。集成了与类无关的区域建议、未知感知分类和未知类的增量学习,以持续更新和调整检测模型。OVOD 旨在通过语言和视觉集成来扩大可检测对象的范围,而 OWOD 则解决了在已知新对象类别时逐步适应的额外挑战,更明确地解决了灾难性遗忘和适应的问题。
OWOD 方法
通常一个OWOD的框架需要由以下几个部分组成:
- class-agnostic region proposal(类别无关):在开放世界场景下,由于未知类别的对象没有先验的类别信息,候选区域生成阶段必须对所有可能的对象保持敏感,而不能只关注某些预定义类别。也就是说,这个模块不依赖于具体的类别信息,而是尽可能地覆盖所有可能的对象区域。
- pseudo-labeling-based
- class-agnostic
- metric learning-based
- unknown-aware classification:在开放世界中,除了对已知类别的对象进行分类外,还必须能够识别出那些不属于任何已知类别的对象,将其标记为“未知”。这样可以防止模型将未知对象错误地归类到已知类别中。通常,分类模块会结合置信度或不确定性信息,当模型对某个候选区域的分类结果信心不足时,可以将其归为“未知”。这就要求分类器具备对未见过样本的识别能力,而不仅仅是进行标准的多分类判别。
- unknown-class incremental learning:开放世界场景中,系统可能在运行过程中接收到新的标签数据,代表以前被认为是“未知”的对象现在已经被标记为新类别。此时,模型需要具备增量学习的能力,即在不从头训练整个模型的情况下,将新的类别加入到识别体系中。传统的增量学习往往面临“灾难性遗忘”问题,也就是在引入新类别后,模型可能会忘记对原有类别的检测能力。因此,在设计增量学习模块时,需要采用特定策略,保证新旧知识的平衡。
pseudo-labeling-based
ORE:引入了一种基于对比聚类和基于能量值的未知识别方法,通过已知类别和未知类别的能量分布可以帮助模型判断某个预测是否应标记为“未知”。如果某个样本的能量值低于已知类别的能量阈值,则该样本会被分类为未知类别
OWOD: 多尺度上下文编码,利用backbone的特征激活值计算的高对象性分数排名靠前的查询被伪标记为未知对象;引入了前景对象性分支,以更好地将前景对象(已知和未知)与背景分开
CAT: CAT 是从 OW-DETR 开发的另一种基于伪标记的 OWOD 方法。作者认为,提取对象定位和识别过程是人类的本能。因此,提出了一个共享的decoder,将对象检测分为两部分。CAT 还将模型驱动和输入驱动的伪标签相结合,其中以注意力驱动的伪标签作为模型驱动的伪标签,选择性搜索作为输入驱动的伪标签。
class-agnostic
PROB: 通过将开放世界的过程分割为对象性的概率与基于对象的类概率的两个过程,同时物体性预测模型被设计为一个多元高斯分布,在查询嵌入空间中进行建模,通过计算查询嵌入与该分布的距离来预测物体性。通过马氏距离,模型可以衡量查询嵌入与目标物体特征之间的相似度
UNDETR:
借助Open Vocabulary的能力
SKDF:
KTCN:
YOLO-World:
YOLO-UniOW:
融合Attribute
FOMO:
UMB: