UN-DETR: Promoting Objectness Learning via Joint Supervision for Unknown Object Detection
引用:Haomiao Liu, Hao Xu, Chuhuai Yue, & Bo Ma (2024). UN-DETR: Promoting Objectness Learning via Joint Supervision for Unknown Object Detection. ArXiv, abs/2412.10176.
动机
作者认为UOD可以被视为一个两步问题:
-
- 以类别无关的方式定位所有对象,包括已知和未知的;
-
- 为这些对象分配特定类别。第一步依赖于如何学习任何对象的泛化特征,即对象性,以区分它们与背景之间的关系。 困难在于,根据UOD的定义,未知对象缺乏监督,它们的对象性大部分是从已知类别泛化而来的。现有的一些方法仍然面临低召回率和精确度的问题,常常将未知对象错误分类为背景或反之。
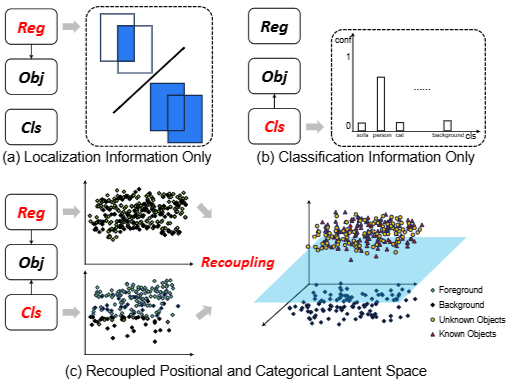
比如:UnSniffer(Liang et al. 2023)仅利用位置信息预测(IoU,即预测结果与真实值之间的交并比)(下图(a)),可能会错误地将没有实例的高IoU框分类为前景。类无关的位置信息对于准确的对象定位至关重要。PROB(Zohar, Wang, 和 Yeung 2023)忽略了位置信息,并将对象性与分类头合并(下图(b)),仅将对象性头集成在分类头内,但没有调整回归头,从而影响了未知对象的定位精度,导致部分或过大的对象预测框。
作者提出UN-DETR,总的来说:引入了实例存在分数(Instance Presence Score,IPS),该分数整合了来自位置和类别潜在空间的代表一般物体性元素。具体来说,我们引入了一个 IPS 预测器(IPS Predictor,IPP),与原始分类头和回归头一起,直接输出 IPS。优化过程通过来自两个空间的信号进行联合监督,确保它们的相互补充性。为了增强 IPS 学习,我们提出了一种一对多分配策略,引入更多正样本。随后,我们提出了无偏查询选择,以通过用学习到的 IPP 替换原始分类头来优化查询的初始化。此外,我们提出了一个 IPS 引导的后处理策略,过滤冗余框,进一步区分已知物体和未知物体。最后,我们使用区域先验和自监督编码器无监督地对整个 UN-DETR 进行预训练,以获得物体性先验。
Overall
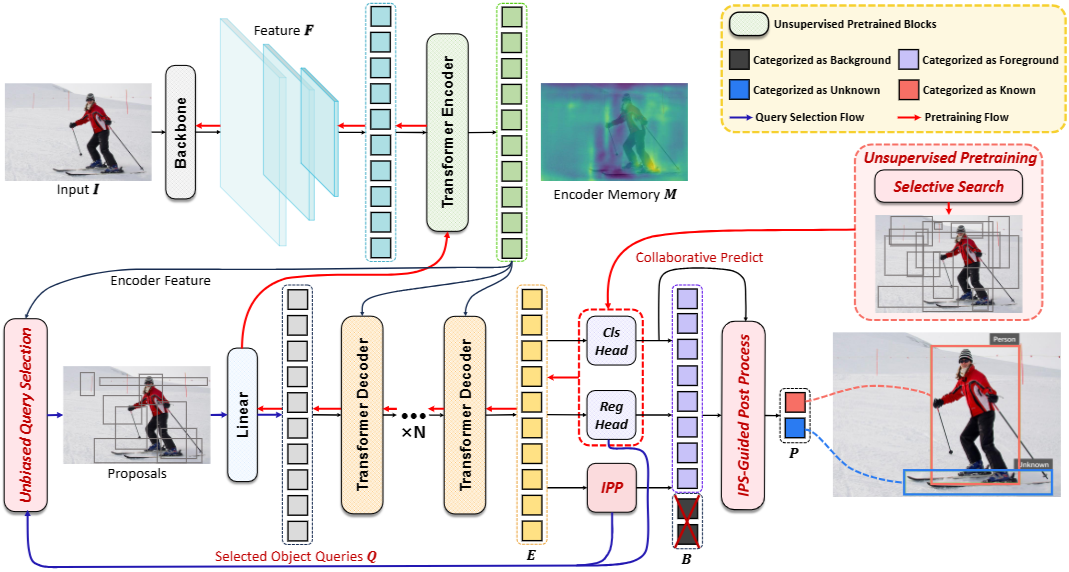
UN-DETR的架构如图2所示。处理流程如下: 输入一张尺寸为 的图像 ,并通过骨干网络提取特征 。这些特征随后由编码器处理,以生成特征记忆 。使用 对前 个初始物体查询进行细化和过滤,然后输入回归头和线性层以生成 个物体查询 。接下来, 个解码器层将 转换为查询嵌入 ,捕获进行准确的未知物体检测(Unknown Object Detection, UOD)所需的空间和语义信息。这些嵌入 经过三个分支—分类、回归和实例存在评分预测(IPP)—以预测潜在实例。预测的边界框 经过由实例存在评分(IPS)指导的后处理,以生成物体实例的最终预测 。在端到端培训之前,UN-DETR模型经过无监督预训练,以建立物体性先验。
Instance Presence Score Predictor
作者从位置或类别潜在空间中提取表示计算物体性分数,并可视化推理过程中特征图的可区分性分数,如下图所示。仅考虑类别潜在空间,如(b)所示,模型在实例与背景之间表现出较高的可区分性分数,但在实例之间的区分则较差。相反,当只使用位置潜在空间表示时,如(c)所示,模型在不同实例之间展现出更大的独特性,但在实例与背景之间的区分较少。这些实验表明,这两个潜在空间在学习物体性方面是互补的。

在对象检测任务中,预测需要定位物体(回归)和识别物体(分类)。这突显了整合位置和类别潜在空间的必要性。
IPP(IPS Predictor)为单层前馈神经网络。它输入查询嵌入 并计算对应的IPS 。查询嵌入 被送入两个头 和 以获取表示 在低维空间 , 中的分类和位置信息.为了去除 和 中与类别相关的部分,我们提取由表示通用性物体性 和 组成的嵌入:
- 对于 ,我们在将其转换为与匹配的GT 的边界框 后计算广义交并比(Generalized Intersection over Union, GIoU)
- 对于,我们通过已知类别数量 的 logits 的总和来表示泛化物体性,因为这 个 logits 表示训练集中所有类别的置信度,而总和则代表前景的整体概率。这避免了模型倾向于偏好某一特定类别或类别:
为了利用 和 的互补性,我们设定目标概率作为 IPP 训练的监督信号:
损失函数:
- 高质量样本损失:当GIoU高于阈值 τ 时,使用目标概率监督IPS
- 低质量样本损失: 当GIoU低于阈值时,使用常数C监督IPS,增强学习的区分性和稳定性
一对多匹配
DETR采用一对一匹配将真实标签与潜在对象关联。IPP 的联合监督过程必须完全依赖于位置和类别潜在空间的特征。这种依赖引入了监督信息的潜在不确定性,阻碍了模型参数朝着更优解的迭代,从而妨碍了训练的稳定性,并对模型性能产生负面影响。
一对多分配允许更灵活地使用所有监督,即使其中一些可能是嘈杂或不确定的。通过允许多个预测捕捉相同的真实标签,模型可以从这些不同匹配中汇聚信息,从而学习到更稳定和全面的对象特征。具体来说,我们在一组最佳匹配查询之外引入了一组次优查询,因为它们也与已知实例以高概率匹配,并且通过双边匹配容易获得。次优查询的索引可以被形式化为:
所有正样本为最有匹配与次优匹配的所有index的并集:
我们仅使用从一对多分配中获得的子最优查询用于联合监督的图像处理与分析(IPP),而不用于分类和回归头。这是因为回归头和分类头的监督直接来源于标签,并且本质上是准确的。因此,引入次优监督可能会对它们的训练产生负面影响。
Unbiased Query Selection
在UQS中,我们用额外的IPP替代原始分类头来过滤Query。IPP的监督信息反映了其与类别无关的特性,因为它的预测表示查询是否代表前景对象的概率,与任何类别特定的先验无关。
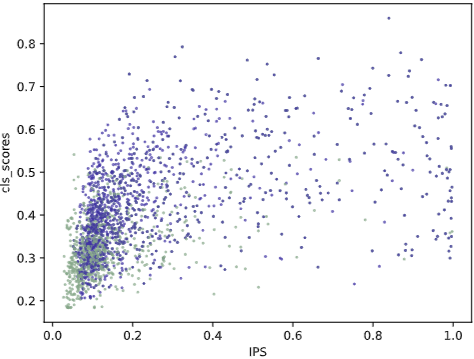
为了分析UQS的有效性,作者在上图中可视化了编码器特征的分类分数和IPS。在散点图中,蓝色和绿色点分别表示使用无偏查询选择和标准查询选择训练的模型的编码器特征。靠近右上角的点表示具有更高质量的特征,这意味着更有可能代表前景对象。值得注意的是,右上角的蓝点数量超过绿色点,表明UQS过滤的查询质量更高,更可能包含实例。
引入额外的IPP,结合位置信息,可以验证查询的空间准确性,减少误检。这减轻了类别特定的偏差,提高了转发给解码器的对象查询质量。
IPS-Guided Post Process
在D-DETR中,前K个边界框直接作为检测结果输出。固定的K限制了召回率,并且手动设置不可靠。作者提出了IPS后处理,其中包括IPS引导的非最大值抑制(NMS),以去除冗余建议和双标准的未知区分协议。
在识别出所有包含前景物体的边界框后,下一步是将其余提案分类为已知和未知类别,通过NMS移除冗余的框。虽然没有专门用于未知对象的分类头,但结合利用IPS和分类置信度仍然可以区分已知和未知。
- 如果分类置信度和IPS都高于设定的阈值,那么该物体将被分配为已知类别。
- 如果分类置信度较低但IPS较高,则该物体被识别为未知,但未被自信地分类。