Towards open world object detection
Joseph, K. J., Khan, S., Khan, F. S., & Balasubramanian, V. N. (2021). Towards open world object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5830-5840)
《Towards Open World Object Detection》(OWOD)论文提出了一种新颖的开放世界物体检测(Open World Object Detection)方法,旨在让物体检测系统在面对未知物体类别时,能够有效地识别这些“未知”物体,并且在逐步学习新类别时避免遗忘已知类别。论文提出的核心方法被称为ORE (Open World Object Detector),该方法通过结合对比聚类、RPN自动标记、energy based的未知识别和增量学习机制来应对开放世界物体检测的挑战。
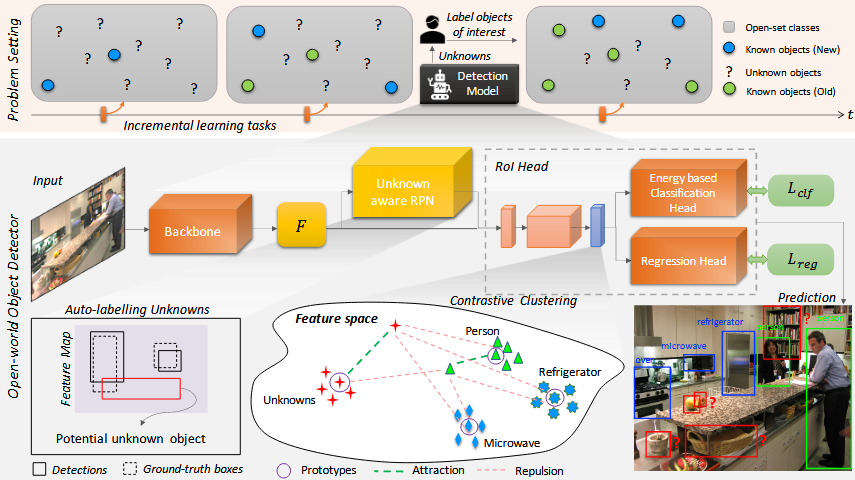
对比聚类(Contrastive Clustering)
对比聚类的损失
其中,是类别c的特征向量,是类别的类原型。每一个类的聚类损失定义为:
其中是特征向量和类原型之间的距离,是一个超参数,用于控制相似和不相似项之间的距离。该损失函数旨在使同一类别的样本聚集在一起,而不同类别的样本尽量分开,从而在特征空间中实现更好的类别分离。
使用RPN自动标记未知物体”(Auto-labelling Unknowns with RPN)中
是一种利用区域提议网络(Region Proposal Network,RPN)自动标记图像中可能属于未知类别的物体的方法。在传统的物体检测任务中,RPN会为每个区域生成多个提议,并通过与真实标签的重叠程度(即IoU,Intersection over Union)来判断是否包含物体并确定物体的类别。在OWOD的开放世界物体检测任务中,模型不仅需要检测已知类别的物体,还需要识别未知类别。关键在于,如何在没有标签的情况下有效标记这些未知物体。
RPN是Faster R-CNN架构中的一部分,主要用于生成候选区域(Region Proposals),即可能包含物体的区域。RPN不依赖于类别标签,而是通过一个类无关的方式为每个图像生成候选框,并为每个候选框计算一个“对象性分数”(objectness score),表示该候选框包含物体的可能性。
作者提出的方案是利用RPN生成的候选框,并结合“对象性分数”来自动标记未知物体。具体来说:
- RPN首先生成多个候选区域,并为每个区域计算一个对象性分数,表示该区域可能包含物体。
- 接下来,对于这些候选区域,RPN会计算它们与已知物体类别的重叠度(通常使用IoU度量)。如果某个候选区域的IoU低于预设的阈值(即与已知类别的物体重叠较少),并且该候选区域的对象性分数较高(意味着它是一个潜在的物体区域),则该区域被标记为“可能的未知物体”。
能量基础的未知识别(Energy-Based Unknown Identification)
ORE使用**能量基础模型(EBM)**来识别未知类别。论文使用了能量基模型(EBMs)来学习能量函数 E(f,L),该函数用于描述观测到的特征 f 与对应标签 l 之间的匹配程度。能量函数输出一个标量值,表示样本是否来自已知类别或是潜在的未知类别。论文采用了赫尔姆霍兹自由能公式,结合所有已知类别的能量来计算总能量。
论文观察到已知类与未知类的能量值有明显的分离,因此通过建模已知类别和未知类别的能量韦布尔分布来提高性能。作者发现,韦布尔分布相较于伽玛分布、指数分布和正态分布,更适合拟合这些能量数据。
能量函数与给定标签 l 的概率密度之间有简单的关系。能量值与网络输出(如softmax层的输出)相关,并且与类别特定的吉布斯分布相联系。该概率密度由以下公式计算:
已知类别和未知类别的能量分布可以帮助模型判断某个预测是否应标记为“未知”。如果某个样本的能量值低于已知类别的能量阈值,则该样本会被分类为未知类别:
Alleviating Forgetting
在开放世界物体检测任务中,当模型识别到未知物体时,它需要在之后逐步学习这些新的类别。需要在学习新类别时不会遗忘旧类别。通过存储每个类别的一小部分示例,并在新类别加入时对这些示例进行微调,从而避免灾难性遗忘。具体步骤如下:
- 存储每个已知类别的一定数量的示例(例如,每个类别10个实例)。
- 每次学习新类别时,使用这些示例进行微调,以保持对旧类别的记忆。
- 随着新类别的学习,逐步更新示例集,以确保模型能够保持对旧类别的识别能力。