OW-DETR: Open-world Detection Transformer
Gupta, A., Narayan, S., Joseph, K. J., Khan, S., Khan, F. S., & Shah, M. (2022). Ow-detr: Open-world detection transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9235-9244)
该文章对于ORE的介绍 最近,ORE的工作引入了一个基于两阶段Faster RCNN的开放世界目标检测器ORE。由于在开放世界范式的训练过程中,未知对象标注是不可用的,因此ORE建议利用自动标记步骤来获得一组用于训练的伪未知数。对区域建议网络(RPN)输出的类别无关的建议进行自动标记。不与已知物体重叠但具有高“客观性”分数的建议被自动标记为未知并用于训练。然后将这些自动标记的未知数与已知的GT一起用于执行潜在空间聚类。 这种聚类试图在潜在空间中分离多个已知类和未知类,并帮助学习未知类的原型。此外,ORE学习了一个基于能量的二元分类器来区分未知类别和未知类别
虽然ORE是第一个引入和探索具有挑战性的OWOD问题表述的,但它存在几个问题。
- 基于能量的分类器中,ORE依赖于一个带有弱监督的持有验证集来估计新类别的分布。
- 为了进行对比聚类,ORE使用单个潜在原型学习未知类别,这不足以对未知对象中常见的多种类内变化进行建模。因此,这可能导致已知和未知之间的次优分离。
- 由于基于卷积的设计,ORE没有明确编码远程依赖关系,这对于捕获包含不同对象的图像中的上下文信息至关重要。在这里,我们着手缓解上述问题,以解决具有挑战性的OWOD问题表述
- ORE 通过从RPN网络中提议中选择具有较高的对象性分数,并且不与Ground-truth重叠作为伪未知物体,获得的这些建议可能偏向于已知类,因为它是在已知类的监督下训练的
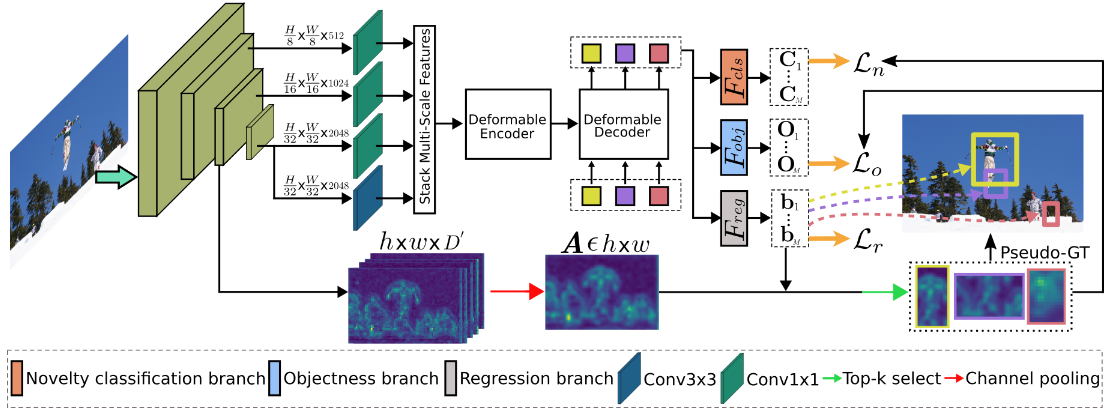
未知物体的识别
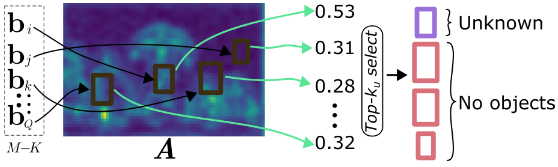
不同于ORE由一个RPN网络为每个区域生成多个提议框,作者认为backbone中提取的特征的激活值可以用来判断是否存在物体,因此对一个box通过公式计算出分数:
回归分支回生成M个候选框,其中有K个已知物体,具有高对象性分数的 M −K 中的 top-k 查询被伪标记为未知对象,其相应的回归分支预测给出了边界框
未知类分类
ORE方法引入了一个基于能量的未知标识符,用于将提案分为已知类和未知类。然而,它依赖于具有弱未知监督的保留验证集来学习已知和未知类别的能量分布。OW-DETR通过在分类器中增加一个0号类作为未知类并用上一节中选择的伪未知类物体训练
前景类预测
作者认为虽然可以通过分类器分类未知物体,但是它不允许将知识从已知对象转移到未知对象,这对于理解 OWOD 设置中未知对象的构成至关重要。因此添加一个预测前景还是背景的分支
代码分析
OWDETR代码基于Deformable DETR实现,下面是整个项目的代码结构以及每个模块的作用概括分析:
.
├── ${EXP_DIR}
├── configs
│ ├── OWOD_our_proposed_split_eval.sh
│ ├── OWOD_our_proposed_split.sh
│ └── OWOD_split.sh
├── data
│ ├── OWDETR
│ └── OWOD
├── datasets
│ ├── torchvision_datasets
│ ├── coco2voc.py # coco数据集注解转换为xml格式
│ ├── coco_eval.py
│ ├── coco_panoptic.py
│ ├── coco.py
│ ├── create_imagenets_t1.py
│ ├── create_imagenets_t2.py
│ ├── create_imagenets_t3.py
│ ├── create_imagenets_t4.py
│ ├── data_prefetcher.py
│ ├── open_world_eval.py
│ ├── panoptic_eval.py
│ ├── samplers.py
│ └── transforms.py
├── exps
│ ├── OWDETR_t1
│ ├── OWDETR_t2_ft
│ └── readme.md
├── models
│ ├── ops
│ ├── backbone.py
│ ├── deformable_detr.py # 网络整体结构
│ ├── deformable_transformer.py
│ ├── matcher.py
│ ├── position_encoding.py
│ └── segmentation.py
├── tools
│ ├── launch.py # 分布式多进程训练创建进程入口
│ ├── run_dist_launch.sh
│ └── run_dist_slurm.sh
├── util
│ ├── box_ops.py
│ ├── misc.py
│ └── plot_utils.py
├── benchmark.py
├── engine.py
├── main_open_world.py # 程序主入口
├── README.md
├── requirements.txt
├── run_eval.sh
├── run.sh
└── run_slurm.sh
数据流向
The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries. Shape= [batch_size x num_queries x (num_classes + 1)]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as(center_x, center_y, height, width). These values are normalized in [0, 1],relative to the size of each individual image (disregarding possible padding).See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of dictionnaries containing the two above keys for each decoder layer.
class DeformableDETR(nn.Module):
# ...
def forward(self, samples: NestedTensor):
# samples 数据集的图片,数据类型NestedTensor(tensors, maskll) coco数据集为例[bs, 3, 800, 872]
if not isinstance(samples, NestedTensor):
samples = nested_tensor_from_tensor_list(samples)
# 提取Resnet layer234的输出features [bs*512*100*109, bs*1024*50*55, bs*2048*25*28]
features, pos = self.backbone(samples)
srcs = []
masks = []
for l, feat in enumerate(features):
src, mask = feat.decompose()
srcs.append(self.input_proj[l](src))
masks.append(mask)
assert mask is not None
# 用最后一层layer4的特征再生成一个特征
if self.num_feature_levels > len(srcs):
_len_srcs = len(srcs)
for l in range(_len_srcs, self.num_feature_levels):
if l == _len_srcs:
src = self.input_proj[l](features[-1].tensors)
else:
src = self.input_proj[l](srcs[-1])
m = samples.mask
mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0]
pos_l = self.backbone[1](NestedTensor(src, mask)).to(src.dtype)
srcs.append(src)
masks.append(mask)
pos.append(pos_l)
# src [bs*512*100*109, bs*1024*50*55, bs*2048*25*28, bs*256*13*14]
query_embeds = None
if not self.two_stage:
query_embeds = self.query_embed.weight # 100个query 每个query是hidden_dim*2维度
# 将backbone提取的特征送入transformer
hs, init_reference, inter_references, enc_outputs_class, enc_outputs_coord_unact = self.transformer(srcs, masks, pos, query_embeds)
然后进入到transformer的结构中
class DeformableTransformer(nn.Module):
# ...
def forward(self, srcs, masks, pos_embeds, query_embed=None):
assert self.two_stage or query_embed is not None
# prepare input for encoder
src_flatten = []
mask_flatten = []
lvl_pos_embed_flatten = []
spatial_shapes = []
for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)):
bs, c, h, w = src.shape
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
src = src.flatten(2).transpose(1, 2) # [bs, c, h, w] -> [bs, hw, c]
mask = mask.flatten(1)
pos_embed = pos_embed.flatten(2).transpose(1, 2)
lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
lvl_pos_embed_flatten.append(lvl_pos_embed)
src_flatten.append(src)
mask_flatten.append(mask)
src_flatten = torch.cat(src_flatten, 1)
mask_flatten = torch.cat(mask_flatten, 1)
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=src_flatten.device) # 存储了上采样后图片的宽高
level_start_index = torch.cat((spatial_shapes.new_zeros((1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))
valid_ratios = torch.stack([self.get_valid_ratio(m) for m in masks], 1)
# encoder
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten)
将展平的特征向量与位置编码输入到编码器中,在encoder中为上采样后的每一层特征的每个像素生成一个参考点
class DeformableTransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
@staticmethod
def get_reference_points(spatial_shapes, valid_ratios, device):
reference_points_list = []
for lvl, (H_, W_) in enumerate(spatial_shapes):
# 生成网格坐标点
ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device),
torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device))
ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H_)
ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W_)
ref = torch.stack((ref_x, ref_y), -1)
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1)
reference_points = reference_points[:, :, None] * valid_ratios[:, None]
return reference_points
def forward(self, src, spatial_shapes, level_start_index, valid_ratios, pos=None, padding_mask=None):
output = src
reference_points = self.get_reference_points(spatial_shapes, valid_ratios, device=src.device)
for _, layer in enumerate(self.layers):
output = layer(output, pos, reference_points, spatial_shapes, level_start_index, padding_mask) # 图像特征,参考点做Multi-Scale Deformable Attention
return output
关于Multi-Scale Deformable Attention的代码可见models/ops部分,是用CUDA算子实现,将计算过注意力的特征输出
class DeformableTransformer(nn.Module):
# ...
def forward(self, srcs, masks, pos_embeds, query_embed=None):
# ...
# ...
# ...
# encoder 输出的是与网格点做MSDA的图像特征
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten)
# prepare input for decoder
bs, _, c = memory.shape
if self.two_stage:
# 两阶段生成提议框,可以不看
else:
query_embed, tgt = torch.split(query_embed, c, dim=1) # 两个可学习的向量 [100, 256] query_embed用来生成参考中心点 ,target用来代表embedding做cross_attn
query_embed = query_embed.unsqueeze(0).expand(bs, -1, -1)
tgt = tgt.unsqueeze(0).expand(bs, -1, -1)
reference_points = self.reference_points(query_embed).sigmoid() # 每个query对应一个参考点
init_reference_out = reference_points
# 进入Decoder
hs, inter_references = self.decoder(tgt, reference_points, memory, spatial_shapes, level_start_index,valid_ratios, query_embed, mask_flatten)
将query_target、每个query对应的参考点、encoder输出传入decoder中
class DeformableTransformerDecoder(nn.Module):
# ...
def forward(self, tgt, reference_points, src, src_spatial_shapes, src_level_start_index, src_valid_ratios, query_pos=None, src_padding_mask=None):
output = tgt
for lid, layer in enumerate(self.layers):
if reference_points.shape[-1] == 4:
reference_points_input = reference_points[:, :, None] \
* torch.cat([src_valid_ratios, src_valid_ratios], -1)[:, None]
else:
assert reference_points.shape[-1] == 2
# reference_points[:, :, None]扩展第三维 [bs, 100, 2] -> [bs, 100, 1, 2]
# 每个查询的每个中心点生成四个参考点
reference_points_input = reference_points[:, :, None] * src_valid_ratios[:, None]
output = layer(output, query_pos, reference_points_input, src, src_spatial_shapes, src_level_start_index, src_padding_mask)
# ...
if self.return_intermediate:
return torch.stack(intermediate), torch.stack(intermediate_reference_points) # 返回6个decoder所有输出
return output, reference_points #, attention_feature
整个transformer返回解码后的query向量(hs)、初始参考点(init_reference_out), 解码后的参考点(inter_references_out),上接第一块代码块。
将transformer返回的数据通过三个分支预测出物体类别、边界框以及是否为前景类
# hs [6, 2, 100, 256] init_reference [2, 100, 2] inter_reference [6, 2, 100, 2]
hs, init_reference, inter_references, enc_outputs_class, enc_outputs_coord_unact = self.transformer(srcs,masks, pos, query_embeds)
outputs_classes = []
outputs_coords = []
outputs_classes_nc = []
for lvl in range(hs.shape[0]):
if lvl == 0:
reference = init_reference
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference)
outputs_class = self.class_embed[lvl](hs[lvl]) # 类别预测分支
## novelty classification
if self.novelty_cls:
outputs_class_nc = self.nc_class_embed[lvl](hs[lvl]) # Novelty Classification分支
tmp = self.bbox_embed[lvl](hs[lvl]) # 回归分支
if reference.shape[-1] == 4:
tmp += reference
else:
assert reference.shape[-1] == 2
tmp[..., :2] += reference
outputs_coord = tmp.sigmoid()
outputs_classes.append(outputs_class)
if self.novelty_cls:
outputs_classes_nc.append(outputs_class_nc)
outputs_coords.append(outputs_coord)
outputs_class = torch.stack(outputs_classes)
outputs_coord = torch.stack(outputs_coords)
if self.novelty_cls:
output_class_nc = torch.stack(outputs_classes_nc)
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1], 'resnet_1024_feat': resnet_1024_feature}
if self.novelty_cls:
out = {'pred_logits': outputs_class[-1], 'pred_nc_logits': output_class_nc[-1], 'pred_boxes': outputs_coord[-1], 'resnet_1024_feat': resnet_1024_feature}
# ......
return out
损失函数
对于目标检测任务,损失函数主要有三类,代码都实现在SetCriterion类中,负责前景类分类、常规分类、回归损失以及分割中的mask损失。
class SetCriterion(nn.Module):
""" This class computes the loss for DETR.
The process happens in two steps:
1) we compute hungarian assignment between ground truth boxes and the outputs of the model
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
"""
def __init__(self, num_classes, matcher, weight_dict, losses, focal_alpha=0.25):
""" Create the criterion.
Parameters:
num_classes: number of object categories, omitting the special no-object category
matcher: module able to compute a matching between targets and proposals
weight_dict: dict containing as key the names of the losses and as values their relative weight.
losses: list of all the losses to be applied. See get_loss for list of available losses.
focal_alpha: alpha in Focal Loss
"""
super().__init__()
self.num_classes = num_classes
self.matcher = matcher
self.weight_dict = weight_dict
self.losses = losses
self.focal_alpha = focal_alpha
def loss_NC_labels(self, outputs, targets, indices, num_boxes, current_epoch, owod_targets, owod_indices, log=True):
"""Novelty classification loss
target labels will contain class as 1
owod_indices -> indices combining matched indices + psuedo labeled indices
owod_targets -> targets combining GT targets + psuedo labeled unknown targets
target_classes_o -> contains all 1's
"""
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (NLL)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
@torch.no_grad()
def loss_cardinality(self, outputs, targets, indices, num_boxes):
""" Compute the cardinality error, ie the absolute error in the number of predicted non-empty boxes
This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients
"""
def loss_boxes(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, h, w), normalized by the image size.
"""
def loss_masks(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the masks: the focal loss and the dice loss.
targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w]
"""
在forward中,接受四个参数:
- samples:原样本 [bs, 3, h, w]
- outputs:模型输出(pred_logits、pred_nc_logits、pred_boxes、resnet_1024_feat、aux_outputs)
- targets:图片真实标签 image_id、labels(多个实例的标签)、area, boxes(每个实例对应4个标量), orig_size, size
- epoch
在这里实现了Attention-driven Pseudo-labeling的部分
def forward(self, samples, outputs, targets, epoch):
""" This performs the loss computation.
Parameters:
outputs: dict of tensors, see the output specification of the model for the format
targets: list of dicts, such that len(targets) == batch_size.
The expected keys in each dict depends on the losses applied, see each loss' doc
"""
if self.nc_epoch > 0:
loss_epoch = 9
else:
loss_epoch = 0
outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs' and k != 'enc_outputs'}
indices = self.matcher(outputs_without_aux, targets) # 匈牙利匹配算法输出([预测框id(0-99)], [真实框排序id(0-物体数)]) * batch_size
owod_targets = deepcopy(targets)
owod_indices = deepcopy(indices)
owod_outputs = outputs_without_aux.copy()
owod_device = owod_outputs["pred_boxes"].device
# Attention-driven Pseudo-labeling ——start
if self.unmatched_boxes and epoch >= loss_epoch:
## get pseudo unmatched boxes from this section
res_feat = torch.mean(outputs['resnet_1024_feat'], 1)
queries = torch.arange(outputs['pred_logits'].shape[1])
for i in range(len(indices)):
combined = torch.cat((queries, self._get_src_single_permutation_idx(indices[i], i)[-1])) ## need to fix the indexing
uniques, counts = combined.unique(return_counts=True)
unmatched_indices = uniques[counts == 1]
boxes = outputs_without_aux['pred_boxes'][i] #[unmatched_indices,:]
img = samples.tensors[i].cpu().permute(1,2,0).numpy()
h, w = img.shape[:-1]
img_w = torch.tensor(w, device=owod_device)
img_h = torch.tensor(h, device=owod_device)
unmatched_boxes = box_ops.box_cxcywh_to_xyxy(boxes)
unmatched_boxes = unmatched_boxes * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32).to(owod_device)
# 存储未匹配的bbox的objectness score
means_bb = torch.zeros(queries.shape[0]).to(unmatched_boxes)
bb = unmatched_boxes
for j, _ in enumerate(means_bb):
if j in unmatched_indices:
upsaple = nn.Upsample(size=(img_h,img_w), mode='bilinear')
img_feat = upsaple(res_feat[i].unsqueeze(0).unsqueeze(0))
img_feat = img_feat.squeeze(0).squeeze(0)
xmin = bb[j,:][0].long()
ymin = bb[j,:][1].long()
xmax = bb[j,:][2].long()
ymax = bb[j,:][3].long()
means_bb[j] = torch.mean(img_feat[ymin:ymax,xmin:xmax])
if torch.isnan(means_bb[j]):
means_bb[j] = -10e10
else:
means_bb[j] = -10e10
# objectness score前top_unk大的未匹配的bbox
_, topk_inds = torch.topk(means_bb, self.top_unk)
topk_inds = torch.as_tensor(topk_inds)
topk_inds = topk_inds.cpu()
# 设置伪标签为分类头中最后一个类,指代unknown([80])
unk_label = torch.as_tensor([self.num_classes-1], device=owod_device)
# 拼接在二分匹配的结果后面
owod_targets[i]['labels'] = torch.cat((owod_targets[i]['labels'], unk_label.repeat_interleave(self.top_unk)))
owod_indices[i] = (torch.cat((owod_indices[i][0], topk_inds)), torch.cat((owod_indices[i][1], (owod_targets[i]['labels'] == unk_label).nonzero(as_tuple=True)[0].cpu())))
# Attention-driven Pseudo-labeling ——end
# Compute the average number of target boxes accross all nodes, for normalization purposes
num_boxes = sum(len(t["labels"]) for t in targets)
num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
if is_dist_avail_and_initialized():
torch.distributed.all_reduce(num_boxes)
num_boxes = torch.clamp(num_boxes / get_world_size(), min=1).item()
# Compute all the requested losses(get_loss调用上面定义的损失函数)
losses = {}
for loss in self.losses:
kwargs = {}
losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes, epoch, owod_targets, owod_indices, **kwargs))
# In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
# ......
# ......
return losses
样本包含的信息: