CAT: LoCalization and IdentificAtion Cascade Detection Transformer for Open-World Object Detection
Ma, S., Wang, Y., Wei, Y., Fan, J., Li, T. H., Liu, H., & Lv, F. (2023). Cat: Localization and identification cascade detection transformer for open-world object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 19681-19690).
论文提到现有的OWOD的方法有下面几个问题
- 已知物体检测能力下降:现有的开放世界物体检测方法在检测未知物体时,通常会导致模型对已知物体的检测能力大幅下降。这是因为在同时进行已知物体和未知物体的检测时,模型容易混淆两者。为了缓解这一问题,CAT提出将开放世界物体检测过程进行拆解,而不是像大多数标准检测模型那样并行进行已知物体和未知物体的定位与识别。通过这种方式,可以减少已知物体和未知物体之间的干扰,从而提高已知物体的检测性能。
- 忽视输入先验条件: 现有的开放世界物体检测模型(如OWOD PLM)通常依赖已知物体的学习过程来指导生成未知物体的伪标签,但这些方法没有利用输入的先验条件(如纹理、光照等)。这样,模型只能从数据标注中学习知识,而无法利用输入数据中的其他有用信息,限制了模型的表现和泛化能力。
- 伪标签的质量不稳定:在现有的伪标签生成方法中,由于伪标签的质量不确定,固定的伪标签选择方式可能导致模型未必能正确学习到如何检测未知物体。这种方式不能保证模型始终朝着正确的方向学习,从而可能导致模型在检测未知物体时表现更差。
shared transformer decoder, cascade decoupled decoding manner self-adaptive pseudo-labelling mechanism
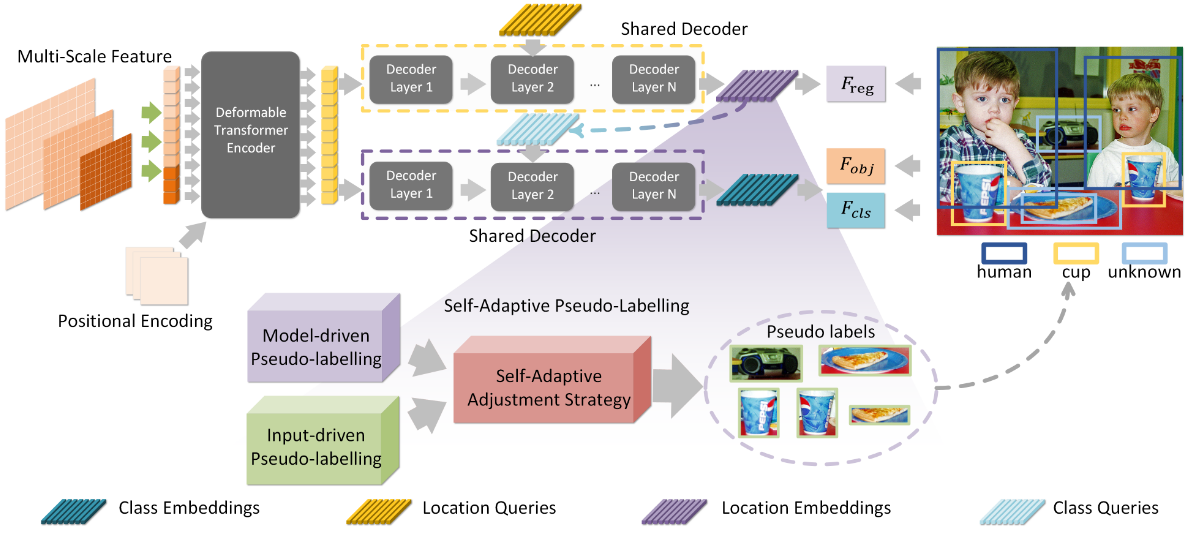
shared transformer decoder and cascade decoupled decoding manner
作者提出通过人类先定位再识别的认知过程,设计了两个共享权重的解码器
人类潜意识地关注所有前景物体,然后详细识别它们,以缓解已知和未知物体之间的混淆,获得清晰的视野。
第一个解码的嵌入用于定位前景对象,而第二个解码的嵌入用于识别对象类别和“未知”。下面的公式表示了这个过程,为共享解码器,为编码器,是backbone,R 表示参考点,J 表示输入图像。
下面的代码包含了在解码过程中的共享权重的解码器(其实是一个解码器),定位解码器的输出作为类别解码器的输入的query
# encoder
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten,mask_flatten)
# prepare input for decoder
bs, _, c = memory.shape
query_embed, tgt = torch.split(query_embed, c, dim=1)
query_embed = query_embed.unsqueeze(0).expand(bs, -1, -1)
tgt = tgt.unsqueeze(0).expand(bs, -1, -1)
reference_points = self.reference_points(query_embed).sigmoid()
init_reference_out = reference_points
# decoder
local_hs, local_inter_references = self.local_decoder(tgt, reference_points, memory, spatial_shapes,level_start_index, valid_ratios, query_embed, mask_flatten)
local_inter_references_out = local_inter_references
local_out = local_hs.transpose(1, 2)
classification_query_embed = local_out[-1]
classification_query_embed = classification_query_embed.permute(1, 0, 2)
classification_tgt = torch.zeros_like(classification_query_embed)
class_hs, class_inter_references = self.local_decoder(classification_tgt, reference_points, memory, spatial_shapes,
level_start_index, valid_ratios, classification_query_embed,
mask_flatten)
self-adaptive pseudo-labelling mechanism
伪标签在指导模型检测未知物体实例时发挥着重要作用,它能够在一定程度上克服模型的学习限制。现有的伪标签方法主要依赖于模型驱动的伪标签生成,但这些方法通常没有充分利用输入数据的先验信息(如光照、纹理等),从而限制了模型的学习能力。
为了改善这一问题,CAT提出了自适应伪标签机制,将模型驱动的伪标签生成与输入驱动的伪标签生成相结合。具体来说,论文采用了基于注意力机制的伪标签生成方法作为模型驱动部分,而选择性搜索方法作为输入驱动部分。这种方法可以根据模型面临的具体情况动态调整伪标签的生成策略。
在自适应伪标签机制中,模型驱动的伪标签生成方法会生成候选框和相应的置信度。输入驱动的伪标签模块根据输入的特征生成候选框。伪标签的置信度计算公式如下:
其中 和 是自适应权重,由 Measurer、Sensor 和 Adjuster 控制,在训练的过程中会存储损失值,再由Measurer、Sensor和Adjuster分别负责评估、监控和调整伪标签生成过程中的权重。
- Measurer的作用是衡量和评估模型训练过程中的损失(loss)趋势。它根据模型训练时的损失值变化来提供伪标签生成过程中权重更新的依据。
- Sensor的作用是通过评估损失的变化量(Δl)来调整权重。它通过监测损失变化的幅度来动态调整权重
- Adjuster的作用是根据Measurer和Sensor的反馈,它将Measurer和Sensor的输出结合起来,调整伪标签生成过程中的权重。
作者先实现了一个Memory_loss类用于保存训练过程中的损失与更新权重:
class Memory_loss:
def __init__(self, length, shuffle=False):
self.shuffle = shuffle
self.length = length
self.Ws = 0.2
self.Wf = 0.8
self.memory = deque(maxlen=length)
Sum1 = sum([i for i in range(1, length+1-20)])
self.weight1 = [i/Sum1 for i in range(1, length+1-20)]
Sum2 = sum([i for i in range(1, 21)])
self.weight2 = [i/Sum2 for i in range(1, 21)]
def add(self, loss):
self.memory.append(loss)
def delta(self):
loss1 = 0
loss2 = 0
for idx, item in enumerate(self.memory):
if idx < self.length-20:
loss1 = loss1 + self.memory[idx]*self.weight1[idx]
else:
loss2 = loss2 + self.memory[idx-self.length+20]*self.weight2[idx-self.length+20]
return loss2/loss1
def Adaptive_weight(self, delta_loss):
delta_weight=0
assert delta_loss >= 0, 'loss should be positive'
if delta_loss > 1:
delta_weight = (1/(1 + math.exp(1-delta_loss)))/2
else:
delta_weight = -delta_loss/3
return delta_weight
def update_weight(self, delta_weight):
self.Ws = self.Ws - delta_weight*self.Ws
self.Wf = self.Wf + delta_weight*self.Wf
total = self.Ws+self.Wf
self.Ws, self.Wf = self.Ws/total, self.Wf/total
在SetCriterion中,每个epoch都会保存上一个epoch的loss,同时与在OWDETR不同的是,在为query分配伪标签使用了真实图片预测区域的像素值与模型特征上采样后的特征值共同预测
def pseudo_label_update(self, Iter, last_loss, epoch):
self.loss_memory.add(last_loss)
if epoch >= self.nc_epoch and Iter % self.adaptive_update_iter == 0 and Iter != 0:
assert Iter > self.memory_length, 'adaptive_start_iter should be laeger than memory length'
delta_loss = self.loss_memory.delta()
delta_weight = self.loss_memory.Adaptive_weight(delta_loss)
self.loss_memory.update_weight(delta_weight)
def forward(self, samples, outputs, targets, epoch, Iter, last_loss):
# ...
if self.enable_adaptive_pseudo :
self.pseudo_label_update(Iter, last_loss, epoch)
if self.unmatched_boxes and epoch >= loss_epoch:
## get pseudo unmatched boxes from this section
res_feat = torch.mean(outputs['resnet_1024_feat'], 1)
queries = torch.arange(outputs['pred_logits'].shape[1])
for i in range(len(indices)):
combined = torch.cat((queries, self._get_src_single_permutation_idx(indices[i], i)[-1])) ## need to fix the indexing
uniques, counts = combined.unique(return_counts=True)
# 未匹配的query的indices
unmatched_indices = uniques[counts == 1]
# ......
# 与OWDETR相同
# ......
# bb 输入驱动
# mean_bb 模型驱动
means_with_swlective = torch.zeros(queries.shape[0]).to(means_bb)
if len(selective_region) == 0:
means_with_swlective = means_bb
else:
IOU = jaccard(bb, selective_region).max(dim=1)[-1]
# 计算伪标签的置信度
means_with_swlective = IOU**self.loss_memory.Ws * means_bb**self.loss_memory.Wf
_, topk_inds = torch.topk(means_with_swlective, self.top_unk)
topk_inds = torch.as_tensor(topk_inds)
topk_inds = topk_inds.cpu()
unk_label = torch.as_tensor([self.num_classes-1], device=owod_device)
owod_targets[i]['labels'] = torch.cat((owod_targets[i]['labels'], unk_label.repeat_interleave(self.top_unk)))
owod_indices[i] = (torch.cat((owod_indices[i][0], topk_inds)), torch.cat((owod_indices[i][1], (owod_targets[i]['labels'] == unk_label).nonzero(as_tuple=True)[0].cpu())))