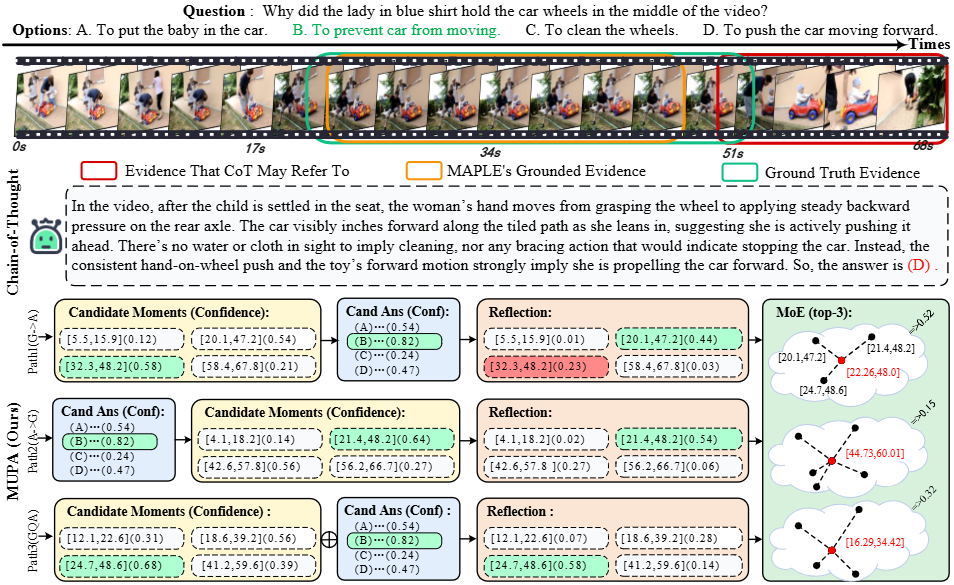
MUPA
sidebar_position: 1
MUPA: Towards Multi-Path Agentic Reasoning for Grounded Video Question Answering
MUPA(MUlti- Path A gentic)是一种协同多路径智能体推理框架,旨在解决Grounded Video Question Answering (Grounded VideoQA) 任务中答案准确性与视觉证据定位不一致的问题。现有最先进的多模态模型在VideoQA中常依赖语言先验和虚假关联,导致预测结果缺乏可靠的视觉依据。
MUPA采用合作式多路径智能体推理方法,整合了视频定位、问答和答案反思与聚合,通过三种独特的推理路径(包括定位优先、回答优先和联合推理)生成候选答案-证据对,并利用一个反思智能体进行验证和融合。
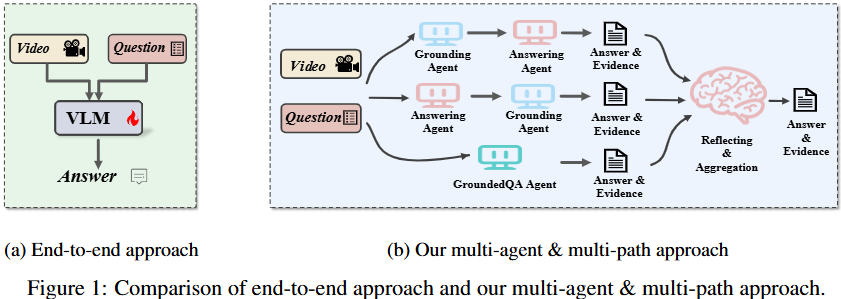
MUPA的核心思想是引入多路径推理和反射机制。该框架包含四个协作智能体:
- Grounder(定位智能体):负责定位视频中的候选事件时刻。
- Answerer(问答智能体):负责预测问题的答案。
- GQA Agent(Grounded QA智能体):同时进行问答和证据定位。
- Reflective Agent(反射智能体):评估和整合不同路径的输出。
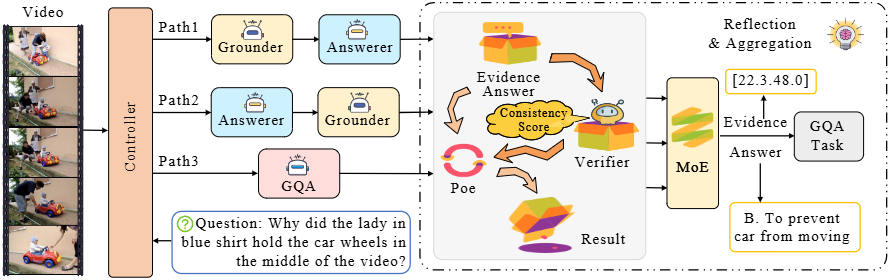
MUPA设计了三条独立的推理路径来处理Grounded VideoQA任务,每条路径都采用不同的推理策略:
- Path-1 (Ground-first-answer-second):遵循“先定位后回答”的策略。首先,将问题转换为查询(例如,去除疑问词和助动词 “The moment when [core clause]”),由Grounder选择K个最匹配的时间片段。然后,这些片段与原始问题一起送入Answerer以生成答案。
- Path-2 (Answer-first-ground-second):采用“先回答后验证”的策略。Answerer首先从完整视频和问题中预测一个初步答案。然后,这个答案被标准化并与问题的核心子句结合,形成一个更具体的查询,传递给Grounder以检索支持性的时间片段。这种路径通过答案信息缩小文本与视频之间的语义鸿沟,提高定位准确性,并能通过降低Grounder的置信度来指示反射智能体处理不可靠证据。
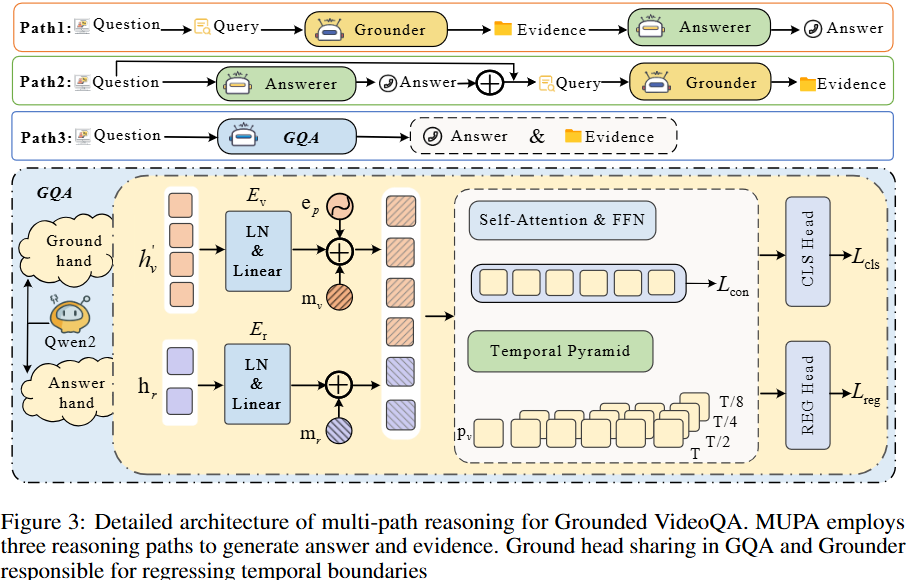
- Path-3 (GQA Agent):通过GQA智能体执行联合推理,以单次传递的方式同时解码答案和证据对。GQA智能体以Qwen2作为骨干模型,将视频帧和文本问题编码为多模态特征,并并行地通过Answer Head和Grounder Head
MUPA 中的每个 agent 都是使用 VideoMind [20] 提出的 Chain-of-LoRA 策略,针对特定角色数据独立训练的。 这种方法允许我们在所有 agent 之间共享一个冻结的视觉-语言 backbone,同时附加轻量级的 LoRA adapters.
GQA Agent
Answer Head 和 Grounder Head 通过加权组合进行同步优化:
- Answer head将[CLS] token映射到答案 logits,使用交叉熵损失进行优化
- Grounder Head 遵循VideoMind设计,通过线性投影和层归一化处理VLM帧嵌入和<REG> token,然后通过自注意力模块和前馈网络生成分类特征,以及通过时间金字塔编码器回归开始和结束时间戳,综合分类损失、回归损失和一致性损失)。整体定位损失为,GQA智能体总损失为。
最终GQA智能体的总损失为下面:
Reflective Agent
**反射智能体(Reflective Agent)**是MUPA的关键组成部分,它负责对多路径输出进行事后验证和整合,确保最终结果的可靠性。它分两个阶段工作:
单路径验证(Single-Path Verification): 验证器(Verifier):评估Grounder生成的N个候选时间片段()。每个片段会向两侧扩展50%,并在边界插入<SEG_START>和<SEG_END>特殊token。验证器处理标记的片段和问题,输出和 logits,计算一致性分数。训练时,IoU > 0.5的片段被视为正例。 PoE重评分(PoE Re-scoring):将Grounder的原始置信度与验证器的一致性分数结合,使用Product-of-Experts (PoE) 机制获得融合置信度。然后,根据对片段进行重新排序,并保留最高置信度的片段及其置信度。PoE机制在路径和验证器都自信时才提升片段,抑制了来自任何单一来源的假阳性。
多路径融合(Multi-Path Fusion): 答案整合(Answer Consolidation):通过加权多数投票机制确定最终共识答案:𝟙。 MoE加权(MoE Weighting):将每个片段的置信度标准化为,作为后续融合中的专家可靠性权重。 加权k-means聚类(Weighted k-means Clustering):将每个时间片段映射到二维点。通过解决加权聚类问题来发现K个共享时刻(聚类中心),其中将每个片段分配给一个聚类。 边界细化(Boundary Refinement):对于每个聚类,通过加权最小二乘问题细化中心,其中是分配给该聚类的所有片段索引集合。最终的证据集由K个精炼后的时间片段组成。