PPO
Training language models to follow instructions with human feedback
总结:提出了一种通过人类反馈(human feedback)微调大型语言模型(LMs),使其更好地遵循用户指令并与用户意图对齐(align)的方法。
-
Which one of the steps is NOT correct for the method introduced in this paper?
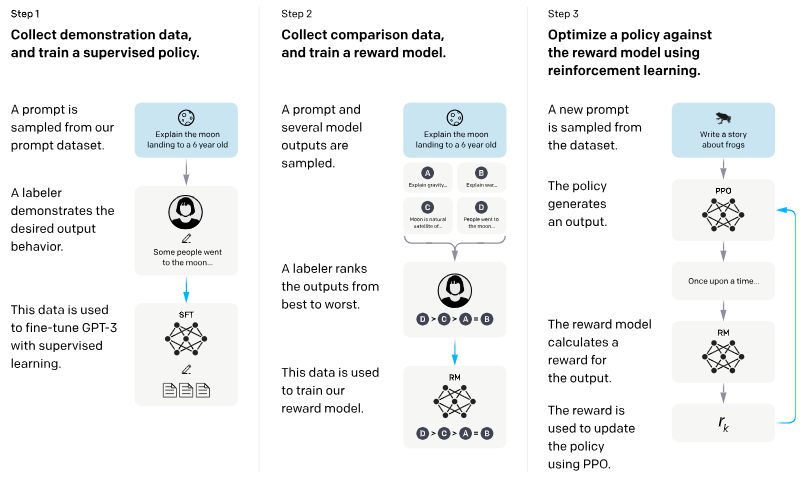
InstructGPT 的训练方法包含三个主要步骤:
- 监督微调(Supervised Fine-Tuning, SFT):用人工标注的提示–回复对来训练模型。
- 奖励模型训练(Reward Model Training, RM):利用人工偏好(对比标注)训练奖励模型。
- 强化学习(RLHF with PPO):用奖励模型来指导语言模型,通过 PPO 优化。
所以如果出现的“错误步骤”是 直接用奖励模型来生成文本,不经过 RLHF 优化 或者 只用监督微调就完成整个流程,那就是 NOT correct 的。
-
Which steps from the previous question can be iterated continuously?
可以反复迭代的步骤是:奖励模型训练 (RM) 与 强化学习 (RLHF) 可以不断迭代。论文中提到,可以收集更多的人类反馈,更新奖励模型,再用新的奖励模型继续优化策略。
-
For reward modeling, if the comparisons are simply shuffled, a single pass over the dataset would cause the reward model to overfit. How is this problem solved according to the paper?

- 问题:如果将所有比较(comparisons)简单地混入一个数据集中,并只做一次完整遍历,奖励模型(reward model)会过拟合。
- 解决方案:对于每个提示(prompt),将其所有 个 pairwise 比较视为同一个 batch 元素(batch element)来训练,而不是分散成多个训练样本。
这样一来:每个提示只需一次前向传递(forward pass),而非次;同时避免了过拟合,提升了验证集上的准确率与 log loss 表现。
-
Use the loss function for the reward model mentioned in Section 3.5. For a given prompt x, the reward model r_sigma assigns scores to two responses y_w and y_l. Suppose the reward for y_w is 3.0 and the reward for y_l is 1.3 , what is the result of the core loss term of this single comparison?