DPO
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
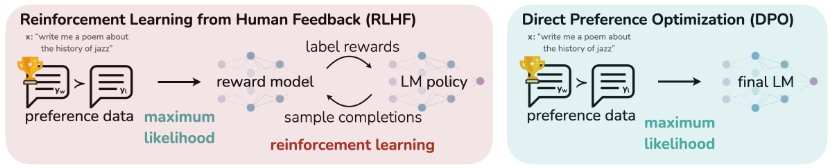
大型无监督语言模型 (LMs) 虽能习得广泛的通用知识和一定的推理能力,但由于其训练的完全无监督性质,精确控制其行为仍面临挑战。现有方法通常通过收集人类对模型生成结果相对质量的偏好标签,并使用强化学习从人类反馈 (RLHF) 来微调 LMs,使其与这些偏好对齐。然而,RLHF 是一个复杂且常不稳定过程,它首先拟合一个奖励模型 (reward model) 来反映人类偏好,然后使用强化学习微调大型无监督 LM 以最大化估计奖励,同时避免与原始模型偏差过远。 本文介绍了一种名为 直接偏好优化 (Direct Preference Optimization, DPO) 的新方法,它对 RLHF 中的奖励模型进行重新参数化,使得可以通过封闭形式 (closed-form) 提取相应的最优策略 (optimal policy),从而仅用一个简单的分类损失函数即可解决标准的 RLHF 问题。DPO 算法稳定、高效且计算开销小,在微调过程中无需从 LM 中采样,也无需进行大量的超参数调整。实验结果表明,DPO 在使 LMs 与人类偏好对齐方面表现与现有方法相同或更好。值得注意的是,DPO 微调在控制生成文本情感方面的能力优于基于 PPO 的 RLHF,并在摘要和单轮对话中匹配或改进了响应质量,同时在实现和训练上显著简化。 核心方法论 (Core Methodology): DPO 的核心在于通过数学推导,将原本需要两阶段(奖励模型学习和强化学习策略优化)的 RLHF 问题简化为一个直接的策略优化问题。
RLHF 基础 (Preliminaries of RLHF): 标准的 RLHF 流程通常包括三个阶段:
-
监督微调 (Supervised Fine-Tuning, SFT): 首先,在一个高质量数据集上对预训练 LM 进行监督学习微调,得到 模型。
-
奖励建模阶段 (Reward Modelling Phase): 使用 生成的响应对 ,收集人类偏好 ,其中 是偏好响应, 是非偏好响应。假设偏好由潜在的奖励模型 生成。在 Bradley-Terry 模型下,人类偏好分布 表示为:
通过最大似然估计拟合参数化的奖励模型 ,其负对数似然损失为:
其中 是 Sigmoid 函数。
-
RL 微调阶段 (RL Fine-Tuning Phase): 利用学习到的奖励函数 为语言模型提供反馈,优化目标是最大化奖励,同时通过 KL 散度约束避免策略 偏离参考策略 (通常是 ):
其中 控制与 的偏差。由于语言生成的离散性,此目标通常使用 PPO 等强化学习算法进行优化。
DPO 目标推导 (Deriving the DPO objective):
在对话大模型(比如 ChatGPT)中,我们通常希望模型输出的回答更符合人类的偏好。传统方法是 RLHF(强化学习人类反馈),但 RLHF 要用奖励模型 + PPO 训练,比较复杂。
DPO(Direct Preference Optimization) 是一种更直接的方法,它不需要奖励模型,而是直接用人类的偏好数据(成对比较)来优化模型。DPO 的关键在于利用奖励函数与最优策略之间的解析映射。对于 KL 约束奖励最大化目标,最优策略 的封闭形式解为:
其中 是配分函数。 通过重排此方程,可以将奖励函数 表示为:
将此重参数化应用于真实奖励 及其对应的最优模型 ,并代入 Bradley-Terry 偏好模型。由于 Bradley-Terry 模型仅依赖于两个完成结果的奖励差,配分函数 项会抵消。因此,最优 RLHF 策略 在 Bradley-Terry 模型下满足偏好模型:
现在,人类偏好数据的概率可以直接用最优策略 而非奖励模型表示。因此,DPO 可以为参数化策略 制定一个最大似然目标,直接优化策略:
:输入 prompt(比如问题)。
:被人类标记为更好的回答(winner)。
:被人类标记为较差的回答(loser)。
:当前训练的模型(带参数 )的概率分布。
= 模型在输入 下生成回答 的概率。
:参考模型(通常是初始模型,比如 SFT 后的模型),作为 baseline。
:表示“当前模型比参考模型更偏向某个回答的程度”。如果大于 0,说明当前模型比参考模型更倾向于这个回答;小于 0 则相反。
:温度系数(超参数),控制模型学习人类偏好的强度。 大 → 学习更激进。
:sigmoid 函数,把值映射到 0-1 区间,用来表示概率。
:对数概率,用来定义 loss。
DPO 更新的作用 (What the DPO update does): DPO 损失函数的梯度会增加偏好完成 的似然,并降低非偏好完成 的似然。重要的是,样本会根据隐含奖励模型 对非偏好完成的评分高低进行加权,即根据隐含奖励模型错误排序完成结果的程度(并由 缩放)进行加权。这种加权对于防止模型退化至关重要。
举一个常见的用与DPO的微调数据集的例子,chosen 为偏好的回复,rejected为拒绝的回复。
{
"chosen": [
{"content": "Q", "role": "user"},
{"content": "good answer", "role": "assistant"}
],
"rejected": [
{"content": "Q", "role": "user"},
{"content": "bad answer", "role": "assistant"}
]
}
下面给出一个简单的dpo-loss的简单pytorch实现
def logits_to_probs(logits, labels):
# logits shape: (batch_size, seq_len, vocab_size)
# labels shape: (batch_size, seq_len)
# probs shape: (batch_size, seq_len)
log_probs = F.log_softmax(logits, dim=2)
probs = torch.gather(log_probs, dim=2, index=labels.unsqueeze(2)).squeeze(-1)
return probs
def dpo_loss(ref_probs, probs, mask, beta):
# ref_probs 和 probs 都是 shape: (batch_size, seq_len)
# https://github.com/jingyaogong/minimind/issues/298
seq_lengths = mask.sum(dim=1, keepdim=True) # (batch_size, 1)
ref_probs = (ref_probs * mask).sum(dim=1) / seq_lengths.squeeze()
probs = (probs * mask).sum(dim=1) / seq_lengths.squeeze()
# 将 chosen 和 rejected 数据分开
batch_size = ref_probs.shape[0]
chosen_ref_probs = ref_probs[:batch_size // 2]
reject_ref_probs = ref_probs[batch_size // 2:]
chosen_probs = probs[:batch_size // 2]
reject_probs = probs[batch_size // 2:]
pi_logratios = chosen_probs - reject_probs
ref_logratios = chosen_ref_probs - reject_ref_probs
logits = pi_logratios - ref_logratios
loss = -F.logsigmoid(beta * logits)
return loss.mean()
问题:
-
What makes this work different from prior RLHF methods? 传统的 RLHF(Reinforcement Learning from Human Feedback)流程通常分为三个阶段:
- 收集人类偏好数据:让人类对模型生成的文本进行排序或评分。
- 训练奖励模型(Reward Model):用这些偏好数据训练一个奖励模型,用于预测某条输出的“好坏”程度。
- 强化学习优化语言模型:通过策略优化(如 PPO)让语言模型最大化奖励模型的输出。
问题在于,RLHF 的训练流程非常复杂:
- 奖励模型的训练可能引入偏差或不稳定性。
- 强化学习优化容易出现高方差梯度、策略崩溃或模式崩溃。
- 超参数调节非常困难,训练成本高。
而 DPO(Direct Preference Optimization) 的不同之处在于:
- 不训练单独的奖励模型,直接使用偏好对进行优化。
- 训练过程简化为监督学习形式的对数似然优化,通过偏好对直接调整模型概率,使更优输出的概率高于劣质输出。
- 保持了模型原有的语言能力,同时避免 RLHF 中的梯度不稳定和策略漂移问题。
简而言之,DPO 用更简单、直接且稳定的方式实现了人类偏好优化。
-
What type of loss function is primarily used to train the language model in the DPO framework?
DPO 的核心是 偏好对数似然损失(Preference Logit Loss),其原理是:
给定一对输出 ,其中 被人类标记为“更好”, 被标记为“较差”,DPO 的损失函数定义为:
其中:
- 是模型的生成概率分布
- 是 sigmoid 函数
- 是输入上下文
通过最小化这个损失函数,模型被训练得相对于输入 x 更倾向于生成人类偏好的输出,而不需要显式计算绝对奖励值。
特点:
- 直接利用偏好对监督模型概率
- 不需要复杂的强化学习优化
- 训练稳定,梯度易于计算
-
What is the role of the reference policy ( ) in the DPO training process?
DPO 使用一个 参考策略 ,通常是原始预训练语言模型或者经过微调的模型,目的是:
- 作为基准概率:损失函数中实际上优化的是“当前模型输出相对于参考策略输出的优势”。
- 控制模型偏离程度:保证模型在优化人类偏好时,不会完全脱离原始语言能力,避免生成不自然或语法错误的文本。
- 稳定训练:通过参考策略对比,可以减少训练中的梯度震荡和过拟合风险。
可以理解为,DPO 并不是直接让模型生成“最优答案”,而是让模型生成比参考策略更符合人类偏好的答案。
-
What was the main finding regarding the use of GPT-4 as an evaluator in the paper's experiments?
论文中使用 GPT-4 来自动评估模型输出,并与人类评价进行对比。主要发现:
- GPT-4 评估结果与人类偏好高度一致,可以在大部分情况下替代人工标注偏好对。
- 大幅提高效率:使用 GPT-4 自动生成偏好对,比人工标注速度快且成本低。
- 可扩展性好:在大规模模型训练和评估中,GPT-4 可以提供可靠的偏好信号,从而使 DPO 训练更高效。
总结来说,GPT-4 可以充当一个“高质量自动评估器”,帮助快速收集训练偏好对。
-
Which one of the prompts of GPT-4 provides win rates more representative of humans?
论文对比了不同的提示方式,发现:
- Pairwise Comparison(两两比较)提示 最能反映人类偏好。
- 在这种提示下,GPT-4 会直接对两条输出进行优劣判断,而不是给出绝对评分。
- 实验显示,使用 Pairwise Comparison 提示计算出的胜率,更接近真实人类评价结果,比其他提示(如评分型 prompt)更可靠。
原因是两两比较更符合 DPO 的训练逻辑:DPO 本质上优化的是偏好对,而不是绝对质量评分。