GRPO
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Group Relative Policy Optimization (GRPO): 为了进一步提升模型性能,DeepSeekMath引入了GRPO算法。PPO通常需要训练一个与策略模型大小相当的价值函数(critic model),带来了巨大的内存和计算负担。GRPO通过放弃独立的价值模型,转而从同一问题下多个采样输出的组得分中估算基线,显著减少了训练资源。 PPO的目标函数为:
其中,是优势函数,通过广义优势估计(GAE)计算,依赖于奖励和学习到的价值函数。PPO通过对每个token的KL散度惩罚来缓解奖励模型的过度优化,奖励函数为:
GRPO的目标函数为:
GRPO通过组内输出的相对奖励计算优势,并直接在损失中添加训练策略与参考策略之间的KL散度惩罚,避免了在奖励中添加KL惩罚以简化的计算。KL散度估计器采用无偏估计:
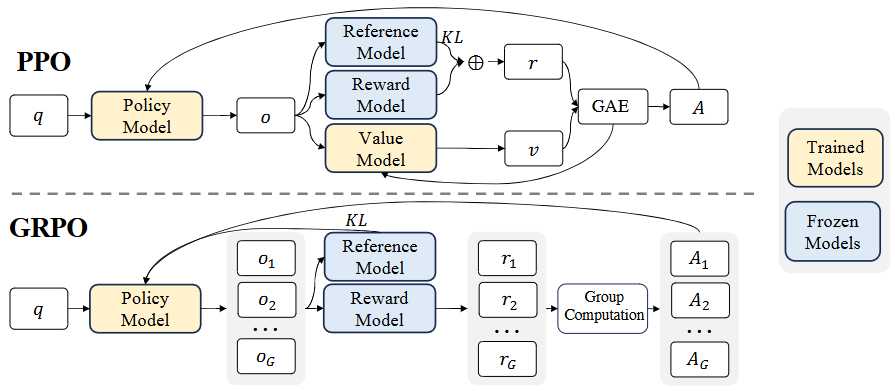
GRPO支持结果监督(Outcome Supervision,OS)和过程监督(Process Supervision,PS),其中PS通过在每个推理步骤结束时提供奖励来提供更细粒度的监督。研究还探索了迭代GRPO,通过不断更新奖励模型和策略模型来提高性能。DeepSeekMath-RL 7B模型在仅使用GSM8K和MATH的思维链格式指令微调数据进行训练后,在所有基准测试中均超越了DeepSeekMath-Instruct 7B,在GSM8K和MATH上分别达到88.2%和51.7%的准确率.
问题
-
Please consider the structures and methods of PPO and GRPO, which ones are correct?
-
PPO(Proximal Policy Optimization):
-
是一种强化学习算法,用于训练策略网络(policy network)。
-
核心思想是通过裁剪(clip)概率比的方法限制策略更新幅度,避免策略突然发生剧烈变化,从而保持训练稳定性。
-
训练过程中通常涉及一个策略网络(actor)和一个值网络(critic),或者使用共享参数的网络。
-
PPO 使用的损失函数为:
其中 。
-
-
GRPO(Generalized Residual Policy Optimization):
- 是在 PPO 基础上的改进方法,用于结合多策略或残差策略进行优化。
- 结构上通常会保留 一个主策略(main policy) 和 一个参考策略(reference policy),训练目标是让主策略在参考策略基础上进一步提升性能。
- 方法上使用的核心思想是:通过参考策略提供基准行为,然后更新主策略以获得更优结果。
✅ 正确理解:
- PPO 核心在于裁剪比率和策略更新限制。
- GRPO 在 PPO 的基础上增加参考策略或残差策略,并利用其作为训练基准。
- 两者都保持策略梯度优化的基本框架,但 GRPO 更侧重多模型协同优化。
-
-
How many models are involved in the GRPO training process, and how many of them are actively trained?
- 涉及的模型数量:通常 2 个模型
- 主策略(policy model):这是需要优化的核心模型。
- 参考策略(reference policy):提供行为基准或残差信号。
- 主动训练的模型:只有 主策略模型被主动更新,参考策略通常保持固定(冻结参数),用作基准。
所以,GRPO 的训练过程中:
- 模型总数:2
- 主动训练的模型数:1(主策略)
-
How does the GRPO algorithm compute its advantage to update the policy model?
- GRPO 的优势计算通常参考 PPO 的方法,但会结合参考策略的行为:
- 基础价值估计:使用价值网络(critic)计算当前状态 的估值 。
- 奖励差分:计算每个动作相对于参考策略的优势。公式可表示为:
其中, 是考虑参考策略行为后的累积奖励,通常形式为:
-
What is the primary benefit of collecting ‘cold-start’ data before RL as stated for DeepSeek-R1?
-
“cold-start”数据指在训练强化学习之前,通过随机策略或预训练策略生成的初始经验数据。
-
主要好处:
- 避免 RL 从零开始:直接训练 RL 可能收敛非常慢,cold-start 数据提供了初始经验缓冲区。
- 提升训练稳定性:为策略提供多样化的状态-动作样本,减少策略在早期过拟合少量奖励信号的风险。
- 加速收敛:模型可以在已有经验基础上进行优化,而不是完全依赖 RL 的探索过程。
简而言之,cold-start 数据为 DeepSeek-R1 提供了初始训练经验和探索指导,让 RL 阶段更高效、更稳定。
-