Exo2Ego
Exo2Ego: Exocentric Knowledge Guided MLLM for Egocentric Video Understanding arxiv 链接
- 😮 鉴于现有多模态大语言模型(MLLMs)在第三人称视觉上表现优异但在一人称(egocentric)视频理解上存在不足,且数据获取成本高,本文旨在通过迁移外在(exocentric)知识来提升对一人称视频的理解能力。
- 🛠️ 为此,作者提出了Exo2Ego框架,包括包含110万同步视角的Ego-ExoClip预训练数据集、一个三阶段渐进式训练流程,以及用于指令微调的EgoIT数据和包含八项任务的EgoBench评估基准。
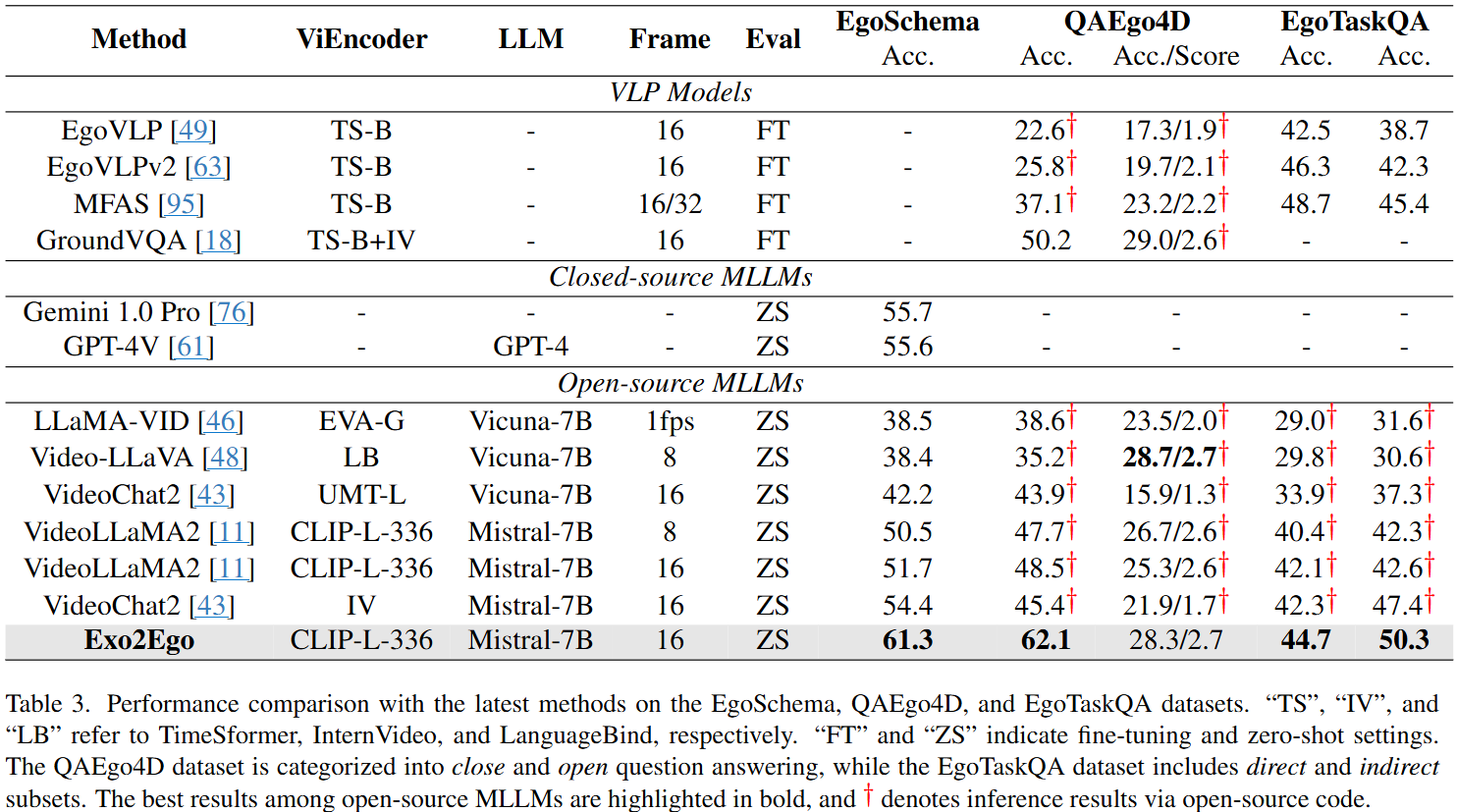
- 📈 广泛实验表明,Exo2Ego模型在多项一人称任务中显著优于现有主流MLLMs,验证了其在具身认知领域推进一人称视频理解的有效性。
本文提出了一种名为Exo2Ego的方法,旨在通过利用多模态大语言模型(Multimodal Large Language Models, MLLMs)中蕴含的丰富第三人称视角 (exocentric) 知识,以低成本方式提升其在第一人称视角 (egocentric) 视频理解方面的能力。当前MLLMs主要聚焦于第三人称(外视角)视觉,忽略了第一人称(自我视角)视频的独特属性,且自我视角数据采集成本高昂,限制了数据规模,从而影响了MLLMs的性能。为解决这些挑战,Exo2Ego提出学习外视角和自我视角域之间的映射,以增强自我视角视频理解。【we propose learning the mapping between exocentric and egocentric domains, leveraging the extensive exocentric knowledge within existing MLLMs to enhance egocentric video understanding】
progressive training process
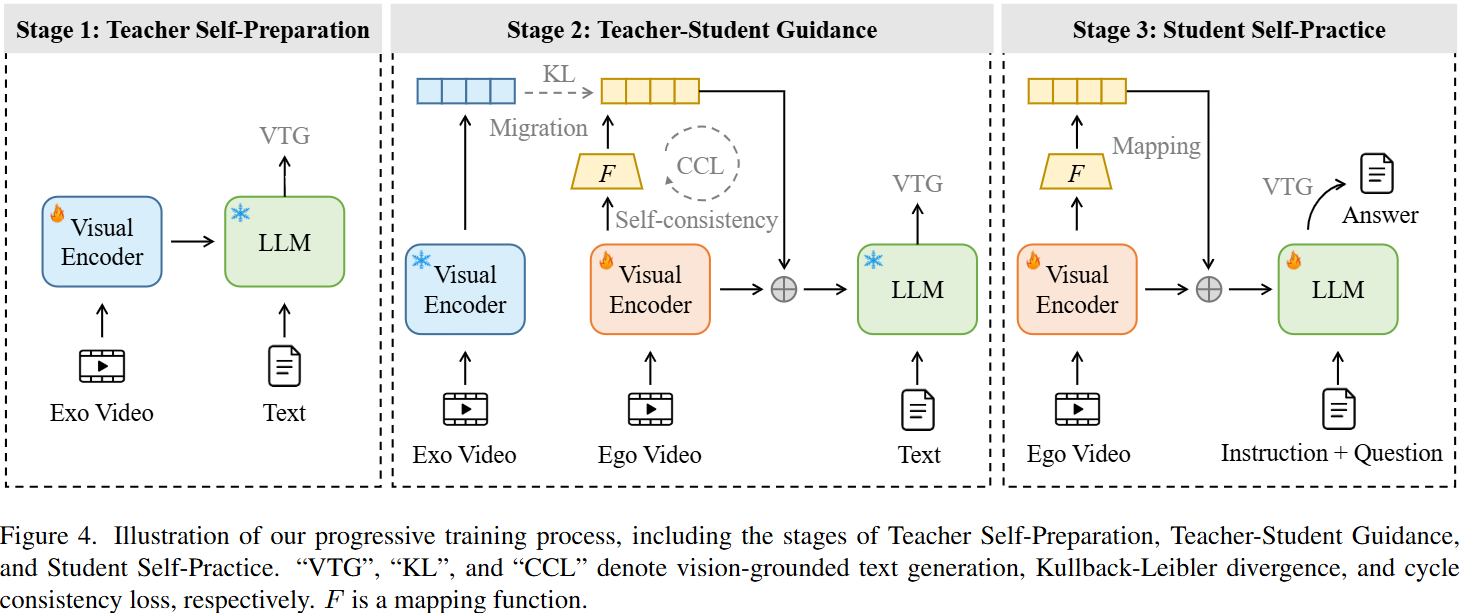
- Initialization
- 第三人称视角视觉编码器:使用VideoLLaMA2 [11] 的方法,利用大规模网络抓取的图像-文本和视频-文本数据集进行训练。
- 第一人称视角视觉编码器:使用EgoClip [49] 数据集进行训练。
在此阶段,大语言模型(LLM)的参数被冻结,仅优化两个视觉编码器。训练后的视觉编码器参数作为后续三阶段的初始化权重。
- Teacher Self-Preparation 此阶段目标是在egocentric data和exocentric data之间建立强大的关联,从而有效地将学生映射到老师(exocentric knowledge can significantly enhance the comprehension of egocentric videos)
-
冻结LLM参数,使用Ego-ExoClip中微调egocentric visual encoder。
-
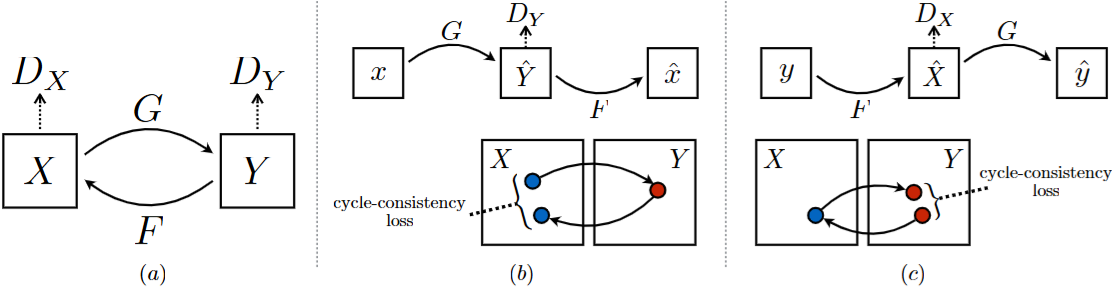
训练了两个由卷积网络组成的特征映射函数,训练loss是CCL
-
采用**视觉-文本生成损失 (Vision-grounded Text Generation, VTG loss)**进行监督,确保数据准确性,下面的公式F指的是第一人称到第三人称,G是F的逆映射
- Student Self-Practice 此阶段致力于增强MLLMs遵循指令的能力,以应对各种自我视角下游任务。 使用EgoIT指令微调数据集。通过拼接自我视角样本(x)及其对应的映射外视角样本(F(x))的表示,为LLM创建全面的语义输入。 对冻结的LLM应用低秩适应 (Low-Rank Adaptation, LoRA) [28](秩设为128,alpha值为256,dropout率为0.1),同时使用VTG损失微调LoRA参数、视觉编码器和映射函数(F)
implement details
The model is built upon the VideoLLaMA2 [11] baseline. We consistently utilized the CLIP-Large-3365 as the visual encoders and Mistral-7B-Instruct6 as the LLM. The mapping functions F and G consist of nine ResNet [26] blocks between the down-sampling and up-sampling sourced operations from [102]. In Stage 3, we incorporated LoRA [27] into the LLM, with a rank set to 128, an alpha value of 256, and a dropout rate of 0.1. All experiments are conducted using the PyTorch [62] framework on 16 A800 GPUs.
experiments