time-r1
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding arxiv 链接
Temporal Video Grounding (TVG) 任务旨在根据自然语言查询定位视频中的特定时间段,是理解长视频的核心挑战。尽管最近的大型视觉语言模型 (LVLMs) 通过监督微调 (SFT) 在TVG上展现出初步潜力,但其泛化能力仍受限。本文提出了一种新颖的后训练框架 Time-R1,通过强化学习 (RL) 增强LVLMs的泛化能力。
现有的时序视频定位 (TVG) 工作主要可以分为两种范式,它们各自存在不同的局限性:
-
基于特征的视频语言预训练 (Feature-based VLP) 范式:
-
范式描述: 这种传统方法首先使用预训练模型(例如,I3D [6]、EgoVLP [29] 用于视频特征,BERT [12] 或 CLIP [42] 用于文本特征)提取独立的视频和语言特征。随后,一个任务特定的定位模型会基于这些融合的多模态特征来预测时间戳。例如,SnAG [37] 采用晚期融合策略并直接回归时间戳。
-
局限性: 这种方法的根本限制在于其错误累积问题。由于视频和语言特征是独立提取的,如果预训练特征本身存在缺陷或不够完善,后续的定位模型性能就会受到影响。
-
-
端到端大型视觉语言模型 (LVLM) 监督式微调 (SFT) 范式
-
范式描述: 近年来,研究重心转向了端到端的 LVLM,这些模型直接处理长视频和文本查询。它们通常通过监督式微调 (SFT) 并使用自回归损失进行训练。为了解决时间戳预测问题,一些方法尝试引入新的时间戳 token 到词汇表 [18, 17, 53] 或添加回归头来预测时间戳 [65]。例如,TRACE [18] 将每个事件视为时间戳、显著性分数和字幕的组合,并微调 LVLM 以自回归方式生成事件序列。
-
局限性:
-
泛化能力有限: 尽管 LVLM 在大型数据集上进行了预训练,并且具有数十亿参数,但在 TVG 任务上,它们的泛化能力仍然受限,甚至常常不如参数量小得多的基于特征的模型(例如,9M 参数的模型 [22])。
-
自回归损失的过惩罚: 作者将 LVLM 表现不佳的关键原因归结为在 SFT 过程中对“假阴性”的过分惩罚。例如,当真实时间戳是 时,即使模型预测一个非常接近的合理时间戳,如 ,自回归损失也会非常高。这种对合理预测的不成比例的惩罚导致模型容易过拟合到训练数据,从而降低了其泛化能力。牺牲预训练语言能力: 引入新的时间戳 token 或回归头的方法,往往会牺牲 LLM 原有的预训练语言能力,因为它们改变了模型处理语言的范式。推理过程不明确: 这些方法通常直接输出时间戳,缺乏一个明确的、可解释的推理过程,使得模型难以理解为什么会做出某个特定预测。总的来说,现有的基于特征的方法受到预训练特征质量的限制,而基于 LVLM 的 SFT 方法则受限于自回归损失的固有缺陷,导致泛化能力差和在合理预测上被过分惩罚。这些局限性促使了 Time-R1 这类通过强化学习来优化任务特定指标的新范式的出现,以期在避免过拟合的同时,更好地利用 LVLM 的强大能力。
-
-
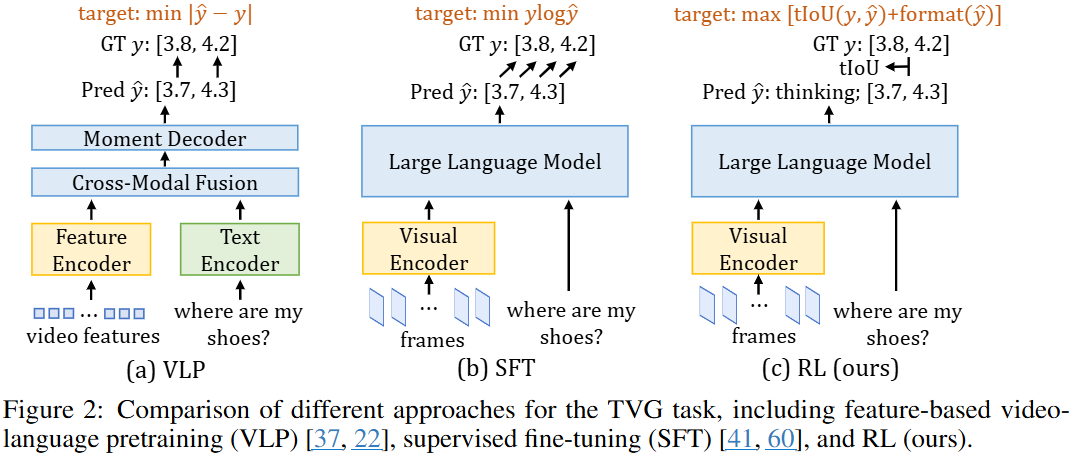
Time-R1 是一个推理引导的RL后训练框架,通过可验证的奖励来优化LVLM。其核心思想是模型在预测时间戳之前先生成一个“思维链”(Chain-of-Thought, CoT)描述,以增强可解释性并促使模型进行上下文推理。
奖励函数设计 (Reward modeling):为了鼓励有效的时序定位和明确的推理过程,设计了复合奖励函数,包含两个部分: 时间戳感知型IoU奖励 (Timestamp-aware IoU reward) : 标准IoU的计算公式为:
其中 是预测时间段, 是真实时间段。为了解决标准IoU在某些情况下可能高估预测质量的问题(例如,当真实时间段很长时,即使预测不精确也可能获得较高IoU),引入了 。它在标准IoU的基础上,对时间戳偏差进行惩罚,定义为:
其中 是视频总时长。这种修改使得奖励信号更加严格和信息丰富,鼓励LVLM形成更深层次的时间理解。
推理模板奖励 (Reasoning template reward) : TVG任务中,相关视频片段通常只占长视频的一小部分。直接预测时间戳而不进行推理是次优的。为了鼓励模型在进行预测前先通过推理来识别相关内容,引入了模板奖励,激励模型生成结构化的中间推理步骤。模型响应必须遵循特定模板(例如,“<think>···</think><answer><ts to te></answer>”)。奖励函数定义为:
总奖励为两者的和:
GRPO训练 (GRPO training): LVLM 接收视频帧和语言查询作为输入,生成 个候选响应 。每个响应的奖励由上述复合奖励函数计算。模型使用广义强化策略优化 (GRPO) 目标进行优化。GRPO鼓励LLM生成最大化加权和奖励 的响应:
为确保训练稳定性并避免与原始语言模型行为产生较大偏差,最终训练目标还包含KL散度正则化项:
其中 是缩放系数, 是当前策略 与参考策略 之间的KL散度。训练过程中,视觉编码器被冻结,仅更新LLM的参数。