EgoMask
info
EgoMask: Fine-grained Spatiotemporal Grounding on Egocentric Videos arxiv 链接
- 🎥 针对第一人称视频中精细时空定位面临的对象持续时间短、轨迹稀疏、尺寸小和位移大等独特挑战,本研究提出了首个像素级基准EgoMask及其配套大规模训练数据集EgoMask-Train,并通过自动化流程进行标注。
- 📊 EgoMask-Train数据集具有第一人称视频的固有特性,例如目标对象在视频中总持续时间短、连续轨迹稀疏、对象尺寸小以及相邻帧间位置变化大。
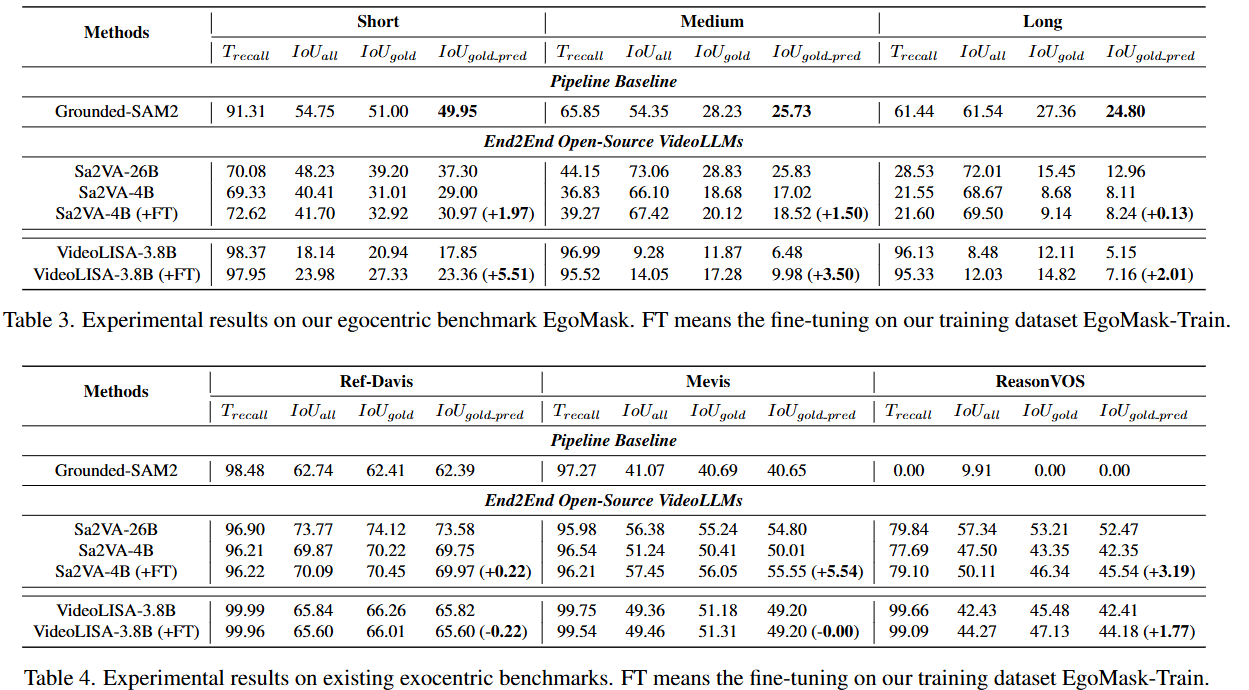
- 🚀 实验表明,现有最先进模型在EgoMask上表现不佳,但通过在EgoMask-Train上进行微调,其性能可显著提升,同时保持在第三人称数据集上的表现,为推进第一人称视频理解提供了宝贵资源和深入见解。
这篇论文探讨了第一人称视角 (egocentric) 视频中的精细时空定位 (fine-grained spatiotemporal grounding) 问题。尽管现有研究在外人称视角 (exocentric) 视频方面取得了显著进展,但第一人称视角视频领域仍相对未被充分探索,而该领域在增强现实 (AR) 眼镜和机器人技术等应用中日益重要。
研究动机与挑战:
作者首先对第一人称视角和外人称视角视频之间的差异进行了系统性分析,揭示了第一人称视角视频的关键挑战:
- 物体总持续时间更短 (shorter total durations): 物体在视频中出现的总时间比例较低。
- 连续轨迹更稀疏 (sparser continuous trajectories): 物体连续出现的片段较少,且持续时间短。
- 物体尺寸更小 (smaller object sizes): 画面中目标物体通常占比较小。
- 位置漂移更大 (larger positional shifts): 由于相机快速移动,相邻帧中物体的 IoU (Intersection over Union) 值较低。 这些挑战使得现有最先进的时空定位模型在第一人称视角视频上表现不佳。
为此,作者在EgoTracks and RefEgo这两个数据集的基础上制作了:
- EgoMask 基准测试集: 这是首个针对第一人称视角视频中精细时空定位任务的像素级基准测试集。它由一个自动标注流程构建,涵盖短、中、长时长的视频,并包含指代表达 (referring expressions) 和物体掩码 (object masks)。
- EgoMask-Train 训练数据集: 一个大规模的训练数据集,旨在促进模型开发,也通过自动标注流程生成。
实验设置:
评估指标: 论文引入了四个指标来评估像素级时空定位性能:
- : 预测帧在所有真实目标帧中的比例,评估时间定位性能。
- : 所有视频帧的平均 IoU 值(传统 J 指标)。论文指出该指标在第一人称视角视频中可能不合适,因为背景帧占比较大。
- : 仅计算真实目标帧中预测掩码与真实掩码的平均 IoU,忽略背景帧。
- : 计算所有真实目标帧和预测帧中的平均 IoU,但排除真实掩码和预测掩码都不存在的帧。该指标更具挑战性,因为它惩罚了在背景帧上的幻觉预测。
基线模型:
- Grounded-SAM2 [43]: 一个流水线追踪器,结合 GroundingDino [27] 进行物体检测,然后使用 SAM2 [42] 进行分割和追踪。
- Sa2VA [59]: 开源的 VideoLLM,结合 LLaVA 和 SAM2,首先在关键帧生成掩码,然后通过 SAM2 进行视频传播。测试了 4B 和 26B 版本。
- VideoLISA [1]: 开源的 VideoLLM,使用 [SEG] token 将 LLaVA-Phi-3-V [40] 和 SAM [19] 连接起来,对独立图像帧进行分割。
微调实现: 在 EgoMask-Train 和其他外人称视角分割数据集上对 Sa2VA-4B 和 VideoLISA-3.8B 进行了微调。