videomind
VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning arxiv 链接
- 🎥 本文提出了VideoMind,一个新颖的视频-语言代理,旨在解决长视频中对视觉证据进行精确时序定位和复杂推理的挑战,通过模拟人类思维过程实现精细的视频理解。
- 🤖 VideoMind引入了包含Planner、Grounder、Verifier和Answerer的角色化工作流,并采用独特的Chain-of-LoRA策略,通过轻量级LoRA适配器高效地在不同角色间切换,从而在灵活性和计算效率之间取得平衡。
- 🌊 在包括视频问答和时序定位在内的14个公共基准测试中,VideoMind取得了最先进的性能,尤其在长视频推理任务上表现突出,其2B模型在某些Grounded VideoQA任务上甚至超越了GPT-4o。
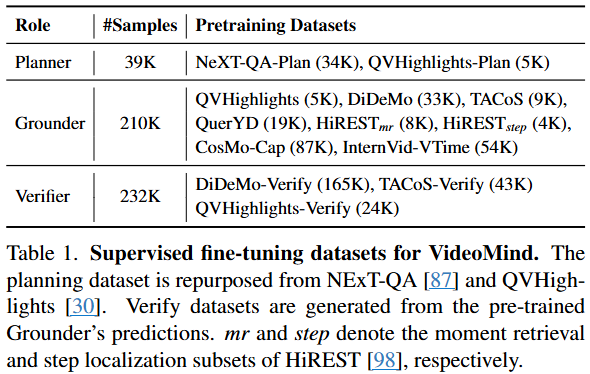
videomind源于广泛采用的Qwen2-VL架构,该架构包括一个 LLM 主干和一个基于 ViT 的视觉编码器,该编码器原生支持动态分辨率输入。给定一个视频输入 V 和一个文本查询 Q,模型自适应地激活不同的角色,并通过调用各个模块来执行逐步推理
Agentic Workflow (Agent 工作流)
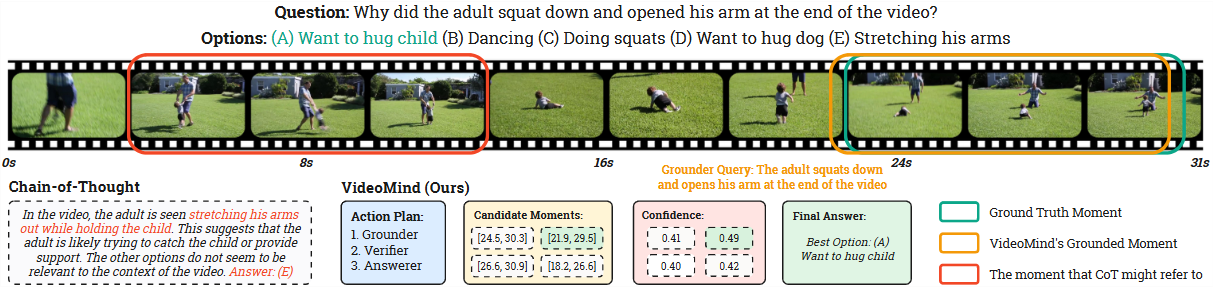
VideoMind 定义了一套角色导向的 Agent 工作流,以满足视频 temporal reasoning 的关键能力需求。
-
Planner:根据查询动态协调其他角色,生成 JSON 格式的行动计划,例如
json[{"type": "grounder", "value": "text query"}, {"type": "verifier"}, {"type": "answerer"}]。它支持“Grounding & Answering”、“Grounding Only”和“Answering Only”三种计划模式,并能重写模糊的查询以提高定位准确性。 -
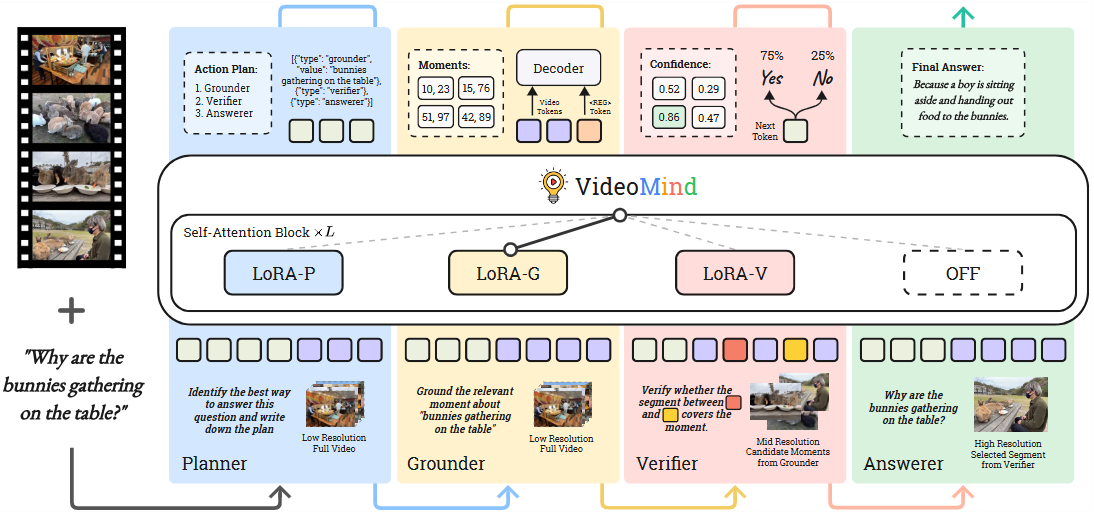
Grounder:负责根据文本查询定位视频中的相关时刻(即起始和结束时间戳)。它配备了一个 Timestamp Decoder,该解码器不直接预测文本时间戳,而是通过一个timestamp解码器头进行预测。
特殊 token ; 生成时,其隐藏状态与所有视觉 token 的隐藏状态 一起输入解码器。视觉 token 首先通过平均池化压缩为每帧一个 token 。然后 和 token 的隐藏状态 经过线性层投影为 和 。这些表示与可学习的模态嵌入 (modality embeddings) 和位置编码 (positional encoding) 一起,通过 Transformer 编码为上下文相关的帧和查询嵌入
为适应不同长度的视频和时刻,Grounder 使用一个 Temporal Feature Pyramid,将 映射到四个不同 temporal resolution 的金字塔层级 (保留原始序列长度的 )。训练目标包括一个用于帧级前景-背景分类的二元 Focal Loss ,一个用于预测 temporal 边界偏移的 L1 Loss ,以及一个用于鼓励学习更具区分性表示的 Contrastive Loss
-
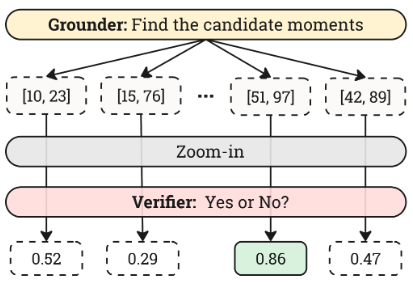
Verifier:对 Grounder 产生的 top-N 候选时刻进行验证和精确化。它通过 Recap by Zoom-in 策略,将每个候选时刻的边界向两边扩展 50%,然后裁剪并放大分辨率。引入特殊 token 和 明确标记时刻的开始和结束。Verifier 的响应是二元的 ('Yes' 或 'No'),通过计算 和 token 的似然值,生成置信度分数 来重新排序候选时刻。
-
Answerer:根据 Grounder 裁剪的视频片段或 Planner 选择的整个视频,以自然语言回答问题。此角色直接使用基础 LMM (Qwen2-VL),无需额外微调。
整个流程如下:
SFT