llava-next-stvg
info
Unleashing the Potential of Multimodal LLMs for Zero-Shot Spatio-Temporal Video Grounding arxiv 链接
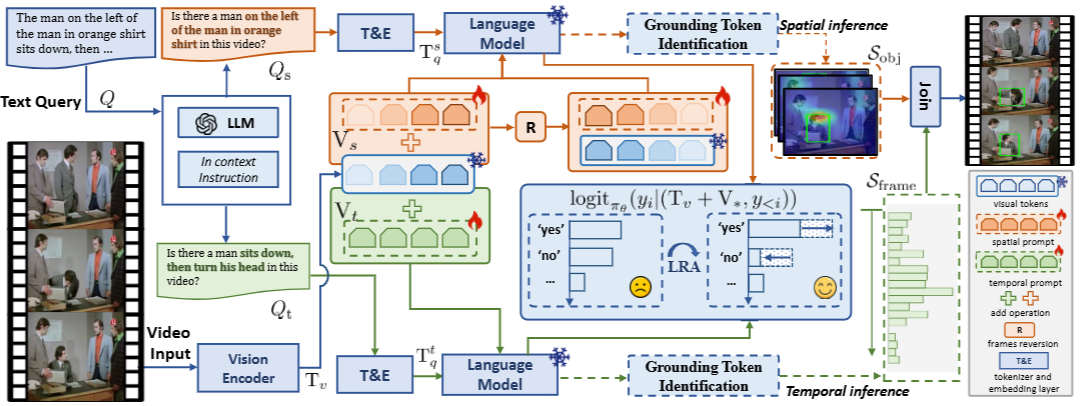
分解时空高亮(Decomposed Spatio-Temporal Highlighting, DSTH):
- 目标相关线索生成:为了解决 MLLMs 忽略复杂查询中属性和动作线索的问题,DSTH 策略首先利用 LLM 的上下文学习能力将原始查询 分解为空间相关的属性子查询 和时间相关的动作子查询 。这些子查询以疑问句形式(如“视频中是否有...?”)输入 MLLM。
- Logit-Guided Re-Attention (LRA) 模块:LRA 模块通过正则化响应生成过程来优化可学习的潜在变量,作为空间和时间提示,以引导模型关注对应的视觉区域。
- 初始化一个与视觉 token Tv 形状相同的可学习变量 (用于空间)和 (用于时间)。
- 将 或 添加到视觉 token 中,作为语言模型的视觉输入。
- 对于每个子查询(例如空间子查询 转换为文本提示 token ),优化目标函数通过对比肯定响应词(如“yes”)和否定响应词(如“no”)的概率来学习提示:
- 其中 是语言模型的参数(冻结), 是生成 token 的对数概率,y_{<i} 是预测时间步 之前的文本 token 序列。
- 在推理过程中,通过反向传播优化 和 ,以增强对目标相关上下文信息的挖掘,从而突出属性和动作线索。