openHOUSE
Open-ended Hierarchical Streaming Video Understanding with Vision Language Models arxiv 链接
这篇论文介绍了一个名为“Open-ended Hierarchical Streaming Video Understanding”(开放式分层流式视频理解)的新任务,该任务结合了在线时序动作定位(Online Temporal Action Localization, On-TAL)与自由形式的描述生成。鉴于现有数据集中缺乏分层且细粒度的时序标注,作者提出了一种利用大型语言模型(LLMs)将原子动作(atomic actions)归类为更高层级事件的方法,从而丰富了现有数据集。在此基础上,论文提出了OpenHOUSE(Open-ended Hierarchical Online Understanding System for Events)系统,旨在将流式动作感知(streaming action perception)从单一的动作分类扩展到更广泛的事件理解。
核心挑战与方法论
该任务面临的挑战主要有三点:
-
分层标注的稀缺性(Scarcity of hierarchical annotations):现有数据集通常缺乏详细的分层时序标注,而这对于训练流式模块理解动作层次结构至关重要。
解决方案:作者提出了一种数据生成流程,利用LLMs的推理能力将原子动作(substep)聚类成更高级别的步骤(step)和目标(goal)标签。该流程包括LLM的聚类阶段和人工验证阶段。实验证明,使用LLM生成的伪标签训练的模型,其性能与使用真实标注训练的模型具有竞争力,验证了该数据生成管道的可靠性。
-
类别无关动作边界建模(Class-agnostic action boundary modeling):在类别无关的在线动作定位中,传统方法(如基于背景-动作帧转换)在过程性视频中表现不佳,因为动作之间通常没有足够的背景帧,导致多个紧密相连的动作被误认为单一连续动作。
解决方案:OpenHOUSE引入了一种新颖的混合动作边界检测策略(Hybrid action boundary detection)。它结合了“动作性”(actionness)和“进展”(progress)两项指标。动作的开始点通过传统的基于动作性的方法检测,而动作的结束点则通过监测动作进展的突然下降来识别。这种方法显著提高了F1分数,尤其适用于动作紧密相连的场景。
-
流式处理和计算效率:在实时流式视频中,持续调用计算成本高昂的视觉语言模型(VLMs)是不切实际的。
解决方案:OpenHOUSE将任务解耦为两个部分:
- 轻量级流式感知模块(Streaming module):该模块实时处理每一帧,执行类别无关的基于OAD(Online Action Detection)的On-TAL。它还跟踪不同层次的动作实例,并决定何时将帧存储到上下文记忆(Context Memory)中。只有当检测到动作实例终止时,该模块才会触发VLM调用。
- 冻结的视觉语言模型(Frozen VLM):VLM(如InternVL2-40B-AWQ)负责根据流式模块提供的相关帧和提示生成自由形式的动作描述。VLM在整个训练过程中保持冻结,利用其强大的零样本推理能力,避免了在小规模自定义数据集上微调可能导致的泛化能力下降。
- 上下文记忆(Context Memory):VLM在生成描述时会利用上下文记忆,其中包含分层感知的帧采样(例如,从当前步骤的子步骤中采样帧)和过去的文本预测作为辅助信息,从而提高描述的质量和上下文一致性,并减少VLM的计算量。
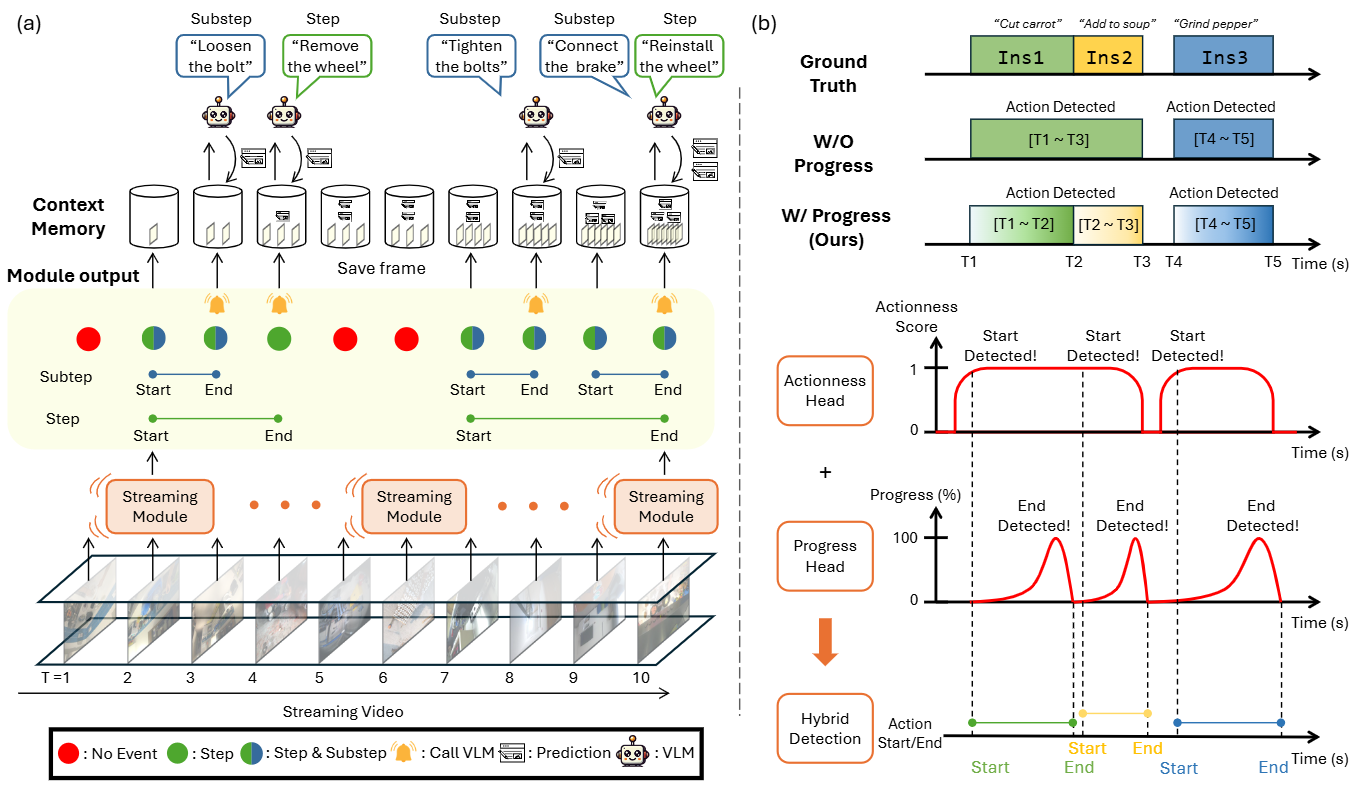
图(a) OpenHOUSE的图示 (Illustration of OpenHOUSE)这部分展示了OpenHOUSE如何协同工作,以实现对流式视频的开放式、分层次理解:
- 流式模块 (Streaming Module):这是系统的“眼睛”,它每帧都在运行,是一个轻量级的模块。它的主要职责是执行类别无关的在线时间动作定位 (class-agnostic On-TAL)。这意味着它不关心具体动作的类别,只专注于检测动作的开始和结束,以及这些动作所处的层次(例如子步骤、步骤)。它会跟踪不同层次上正在进行的动作实例,并根据需要决定是否要调用计算成本较高的VLM。图中的黄色小铃铛图标指示了VLM被触发进行推理的时间点(例如T=3, 4, 8, 10)。当检测到一个动作实例结束时,它会返回一个类别无关的动作实例及其层次级别。
- 上下文记忆 (Context Memory):这个模块用于存储相关信息,包括过去的帧和之前的VLM预测结果。当流式模块检测到动作结束并需要VLM生成描述时,它会从上下文记忆中检索相关信息。
- 冻结的VLM (Frozen VLM):这是系统的“大脑”,一个强大的视觉语言模型。它的特点是“冻结”的,这意味着它不经过微调,利用其强大的零样本推理能力来生成描述。这保留了VLM的泛化能力,避免了在小规模数据集上微调可能导致的性能下降。VLM仅在流式模块检测到动作终止并发出调用信号时才被激活,从而节省了计算资源。它接收检索到的相关帧和之前的文本预测,以及针对特定层次量身定制的提示词,然后生成对应视频片段的开放式描述。生成的预测结果随后会添加到上下文记忆中以供将来参考。
图(b) 混合动作边界检测的工作原理图 (Diagram depicting how our hybrid action boundary detection works)这部分解释了OpenHOUSE如何准确地识别动作的开始和结束,尤其是在动作紧密相连的程序性视频中:
- 传统方法的挑战 (W/O Progress):图中间“W/O Progress”部分展示了传统方法(例如,仅基于“动作存在性/actionness”检测背景帧到动作帧的转换)的不足。在程序性视频中,动作实例往往紧密相连,中间几乎没有背景帧(例如,“Ins1”和“Ins2”之间)。传统方法在这种情况下会将其错误地识别为单个连续的动作实例(如图中所示,它将“Ins1”和“Ins2”识别为一个长动作),无法区分出个体动作的边界。
- 混合动作边界检测 (W/ Progress - Ours):为了解决这个问题,OpenHOUSE引入了一种混合策略,结合了“动作存在性 (Actionness)”和“动作进度 (Progress)”。动作存在性头部 (Actionness Head):主要用于检测动作的开始。当背景帧突然转换为动作帧,或检测到高动作存在性分数时,被标记为动作开始。进度头部 (Progress Head):主要用于检测动作的结束。它监测动作的“进度”分数,当进度分数突然下降时,这通常意味着一个动作的结束。
具体示例 (T1-T5):
- T1:动作开始,由动作存在性头部检测到。动作进度开始增加。
- T2:动作的进度突然下降,信号着当前动作的结束。此时,当前的帧被标记为背景帧。
- T2之后的一个时间步:由于高动作存在性分数,该帧再次被分类为动作帧,形成一个从背景到动作的转换,从而标记了Ins2的开始。
- T3:进度下降,Ins2结束。
- T4:动作存在性检测到Ins3开始。
- T5:进度下降,Ins3结束。
实验与分析
论文在Ego4D-GoalStep (EgoGS)、Ego-Exo4D Keystep (EgEx) 和 Epic-Kitchens 100 (EK100) 等数据集上进行了广泛实验